Rによる統計モデリング入門 2026 栃木県
https://heavywatal.github.io/slides/tochigi2026/
本日のおしながき
岡本さんからご依頼いただいた内容をもとに構成
前半は統計そのもののお話を中心にしていただき、後半にRの使い方を
今回は「90分で、Rの苦手意識を払拭する」ことが目標です。
- 90分6–8コマの講義からの
やや無理のあるダイジェスト - 科学研究におけるデータ解析とモデル
- データ可視化の重要性
- Rを使う心構えと基本操作
すべてを理解しようとせず「あとで調べればいいや」くらいの気持ちで。
「Rができる人にはできそう」というイメージが持てればOK👍
研究という仕事をざっくり捉えると
- 課題を見つける、仮説を立てる
- 実験🧫・観察🔬・文献📚などからデータを集める
- データを整理・解析して仮説を検証する
- 結果を報告する、1に戻る
つまり、
- 白衣を着て分子実験をやる人も、野山を駆け回って観察する人も、
そのパートは研究の半分くらい。 - 残り半分はデータの整理・解析・報告。
→ しかし軽視されがち。ここをちゃんと、でも楽にやりたい。
データ解析って必要? 生データ見ればいいべ?
生のままでは複雑過ぎ、情報多すぎ、何もわからない。
print(ggplot2::diamonds)
carat cut color clarity depth table price x y z
1 0.23 Ideal E SI2 61.5 55 326 3.95 3.98 2.43
2 0.21 Premium E SI1 59.8 61 326 3.89 3.84 2.31
3 0.23 Good E VS1 56.9 65 327 4.05 4.07 2.31
4 0.29 Premium I VS2 62.4 58 334 4.20 4.23 2.63
--
53937 0.72 Good D SI1 63.1 55 2757 5.69 5.75 3.61
53938 0.70 Very Good D SI1 62.8 60 2757 5.66 5.68 3.56
53939 0.86 Premium H SI2 61.0 58 2757 6.15 6.12 3.74
53940 0.75 Ideal D SI2 62.2 55 2757 5.83 5.87 3.64
ダイヤモンド53,940個について10項目の値を持つデータセット
要約統計量を見てみよう
各列の平均とか標準偏差とか:
stat carat depth table price
1 mean 0.80 61.75 57.46 3932.80
2 sd 0.47 1.43 2.23 3989.44
3 max 5.01 79.00 95.00 18823.00
4 min 0.20 43.00 43.00 326.00
大きさ carat と価格 price の相関係数はかなり高い:
carat depth table price
carat 1.00
depth 0.03 1.00
table 0.18 -0.30 1.00
price 0.92 -0.01 0.13 1.00
生のままよりは把握しやすいかも。
分布を特徴づける代表値 central tendency
- 平均値 mean
- 和を観察数で割る
- 中央値 median
- 順に並べて真ん中
- 最頻値 mode
- 最も頻度が高い値
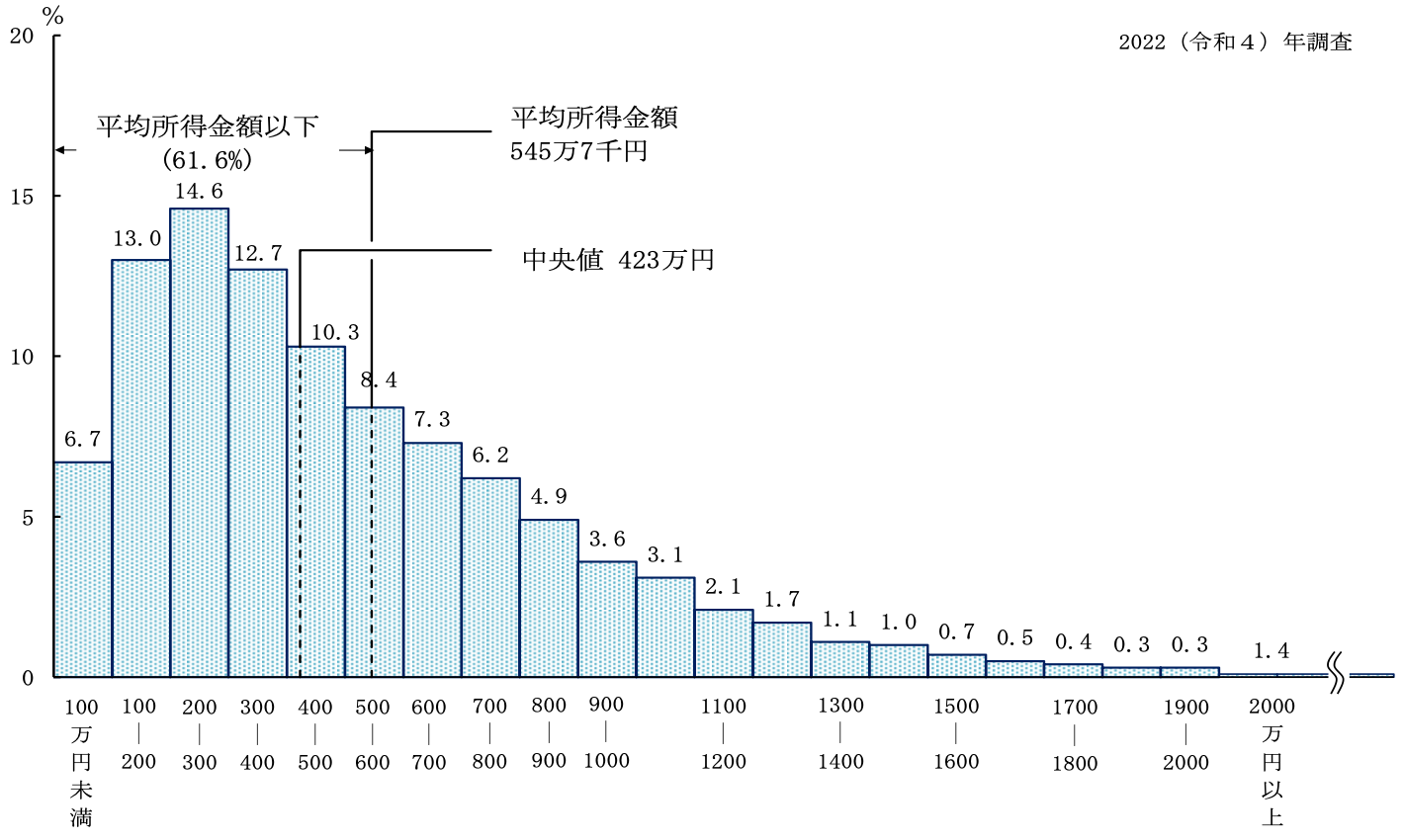
- 外れ値に対する応答
- もし総資産額20兆円の大富豪が鳥取県に引っ越してきたら
→ 県民の平均資産は4000万円上昇。中央値・最頻値はほぼそのまま。
目的や状況に応じて使い分けよう。
ばらつきを捉える記述統計量
- 分散 variance
- 平均値からの差の自乗の平均。 $\frac 1 n \sum _i ^n (X_i - \bar X)^2$
- これの平方根が標準偏差 (standard deviation)。
- Percentile, Quantile (四分位)
- 小さい順にならべて上位何%にあるか。
- 中央値 = 50th percentile = 第二四分位(Q2)
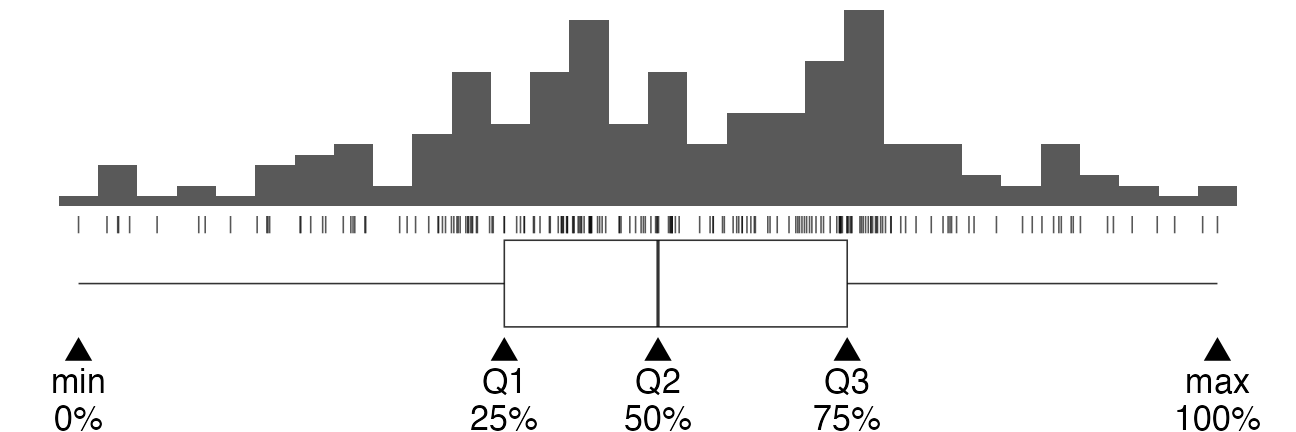
ばらつきの様子は大小の判断にも重要
たまたまかも。
群間の差は微妙か。
群間には差がありそう。
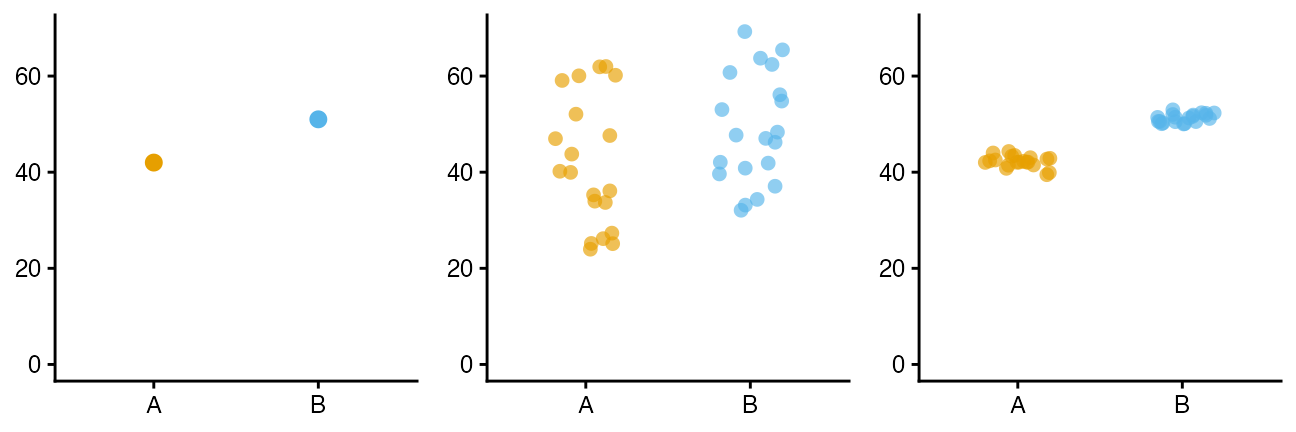
「こんなことがたまたま起こる確率はすごく低いです!」
をちゃんと示す手続きが統計的仮説検定。
でも要約統計量とか検定結果だけを見て判断するのは危険…
要約統計量だけ見て可視化を怠ると構造を見逃す


データ可視化は理解の第一歩
情報をうまく絞って整理 → 直感的にわかる
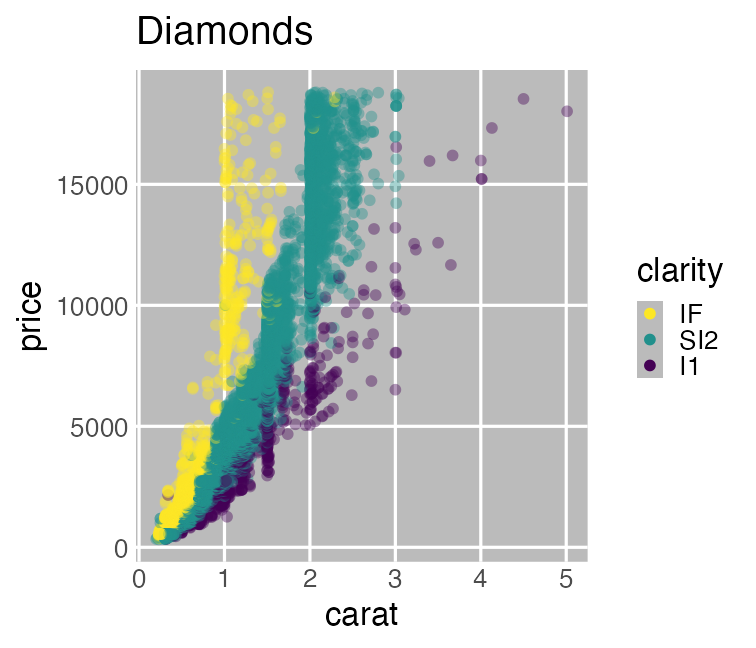
carat が大きいほど price も高いらしい。
その度合いは clarity によって異なるらしい。
統計とは
データをうまくまとめ、それに基づいて推論するための手法。
- 記述統計: データそのものを要約する
- 要約統計量 (e.g., 平均、標準偏差、etc.)
- 作図、作表
- 推測統計: データの背後にある母集団・生成過程を考える
- 数理モデル
- 確率分布
- パラメータ(母数)
「グラフを眺めてなんとなく分かる」以上の分析にはモデルが必要
モデルとは
対象システムを単純化・理想化して扱いやすくしたもの
- Mathematical Model 数理モデル
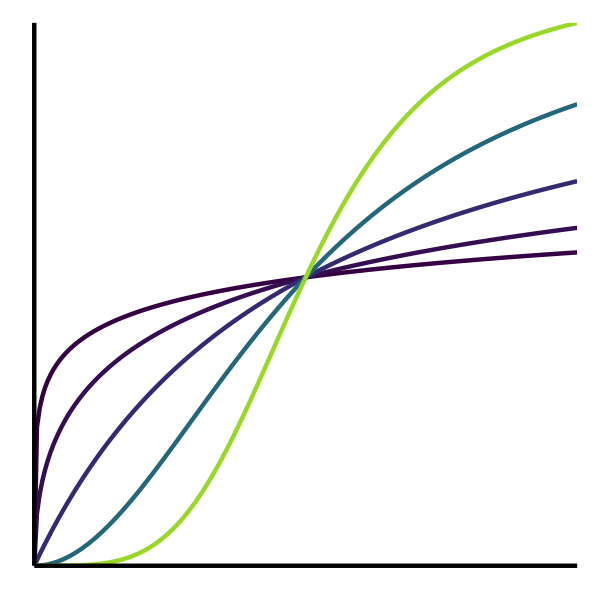
- 数学的な方程式として記述されるもの。
- e.g., Lotka-Volterra eq., Hill eq.
- Computational Model 数値計算モデル
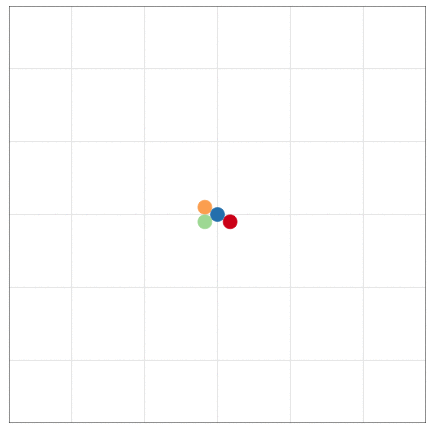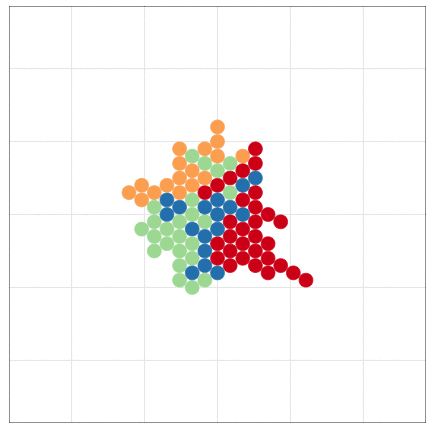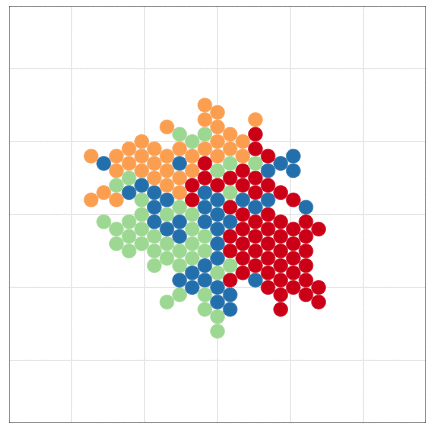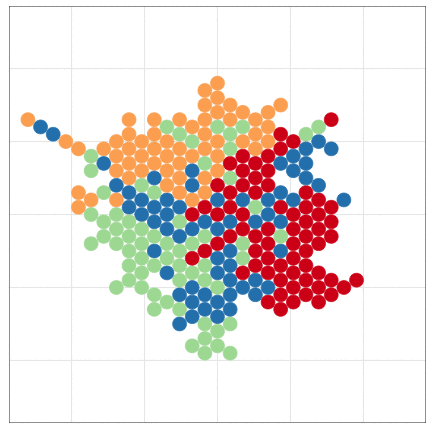
- 数値計算の手続きとして記述されるもの。
- e.g., Schelling’s Segregation Model, tumopp
- Concrete Model 具象モデル

- 具体的な事物で作られるもの。
- e.g., San Francisco Bay-Delta Model
ウェットな実験もモデルの一種と見なせる
対象システムを単純化・理想化して扱いやすくしたもの
→ 自然ではありえない状況にしてでも、見たい関係を見る
→ 「Xを変えればYが変わる」という還元的な理解の1ステップ
- ノイズをなるべく除去
- 栄養や温度など、環境を揃える
- 近親交配を繰り返して純系を作り、遺伝的背景を揃える
- 興味のある要因のみ変えて、表現型の違いを評価
- 遺伝子1つ2つだけ改変
- 投与する薬剤の種類・量を変えてみる
- 栄養塩の濃度と光の強さを変えてみる
ドライの理論研究者を指して「モデル屋」と呼びがちだが、
広い意味では生物学者みんな「モデル屋」。
データ科学における数理モデル
データ生成をうまく真似できそうな仮定の数式表現。

データ科学における数理モデル
データ生成をうまく真似できそうな仮定の数式表現。
e.g., 大きいほど高く売れる: $\text{price} = A \times \text{carat} + B + \epsilon$
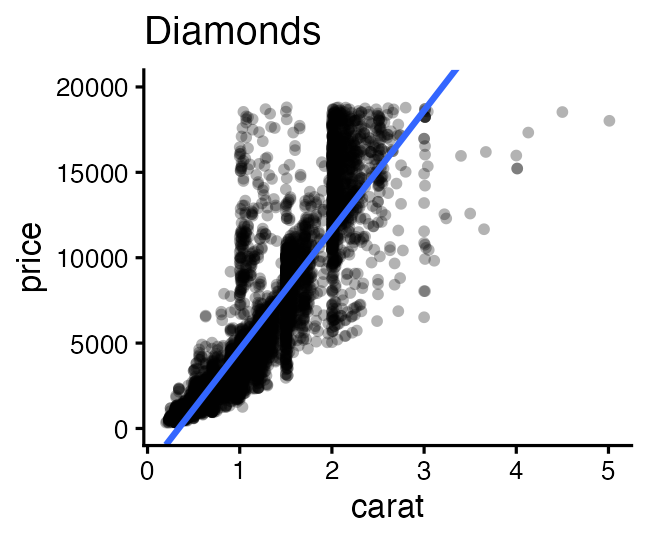
新しく採れたダイヤモンドの価格予想とかにも使える。
このように「YをXの関数として表す」ようなモデルを回帰と呼ぶ。
何でもかんでも直線あてはめではよろしくない
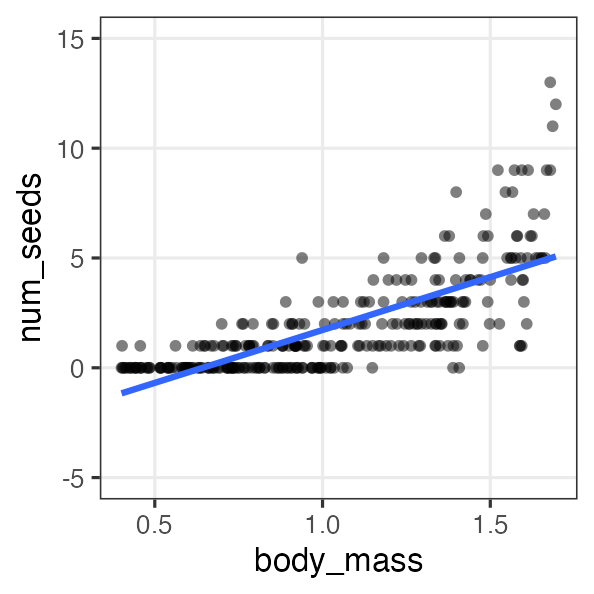
- 観察データは常に正の値なのに予測が負に突入してない?
- 縦軸は整数。しかものばらつきが横軸に応じて変化?
何でもかんでも直線あてはめではよろしくない
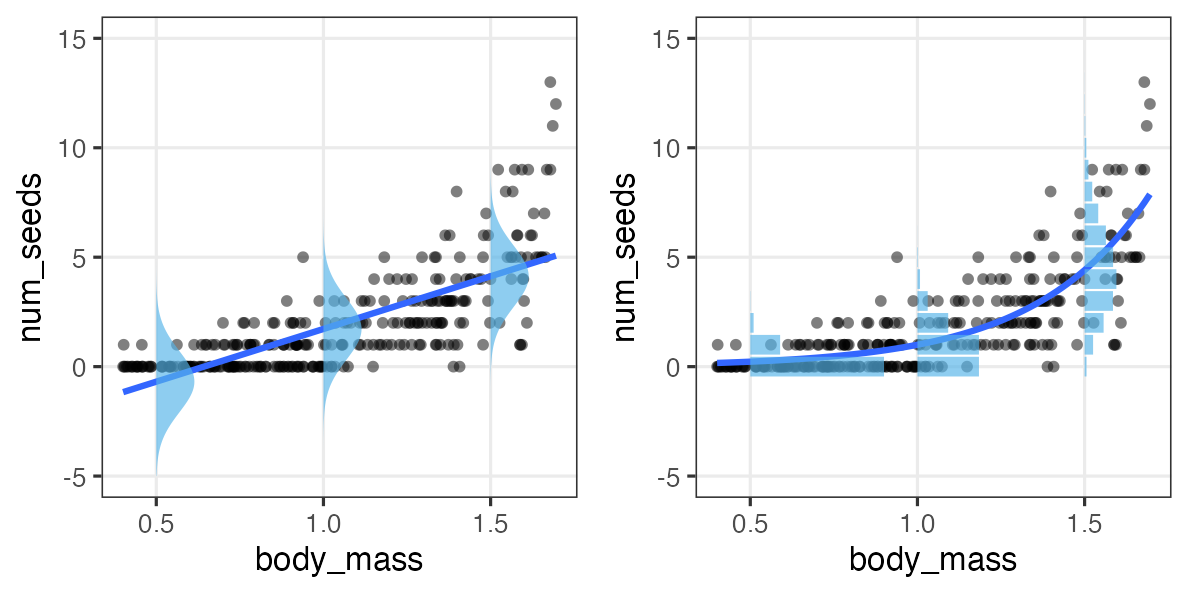
- 観察データは常に正の値なのに予測が負に突入してない?
- 縦軸は整数。しかものばらつきが横軸に応じて変化?
- データに合わせた統計モデルを使うとマシ
統計モデリングの教科書決定版: 久保先生の緑本
ちょっとずつ線形モデルを発展させていく。

線形モデル LM (単純な直線あてはめ)
↓ いろんな確率分布を扱いたい
一般化線形モデル GLM
↓ 個体差などの変量効果を扱いたい
一般化線形混合モデル GLMM
↓ もっと自由なモデリングを!
階層ベイズモデル HBM
最小二乗法
最尤推定法
MCMC
今回はごく一部のみチラ見せ。理解を目指さなくていいです。
説明変数が1つある一般化線形モデル GLM
個体$i$の種子数$y_i$は平均値$\lambda_i$のポアソン分布に従う。
平均値の対数$\log(\textcolor{#3366ff}{\lambda_i})$はその個体の大きさ$x_i$に比例する。

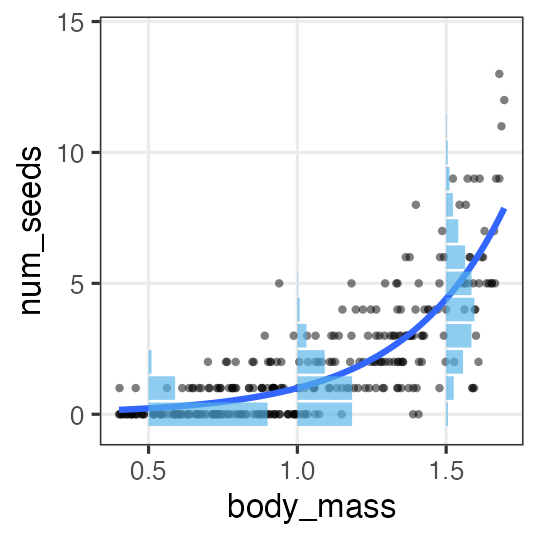
この場合は単回帰。説明変数が複数あると重回帰。
複数の説明変数を同時に扱う重回帰
\[\begin{split} y_i &\sim \text{Poisson}(\lambda_i) \\ \log(\lambda_i) &= \beta_0 + \beta_1 x_{1i} + \beta_2 x_{2i} + \ldots \end{split}\]
気温も湿度も高いほどビールが売れる架空データ:
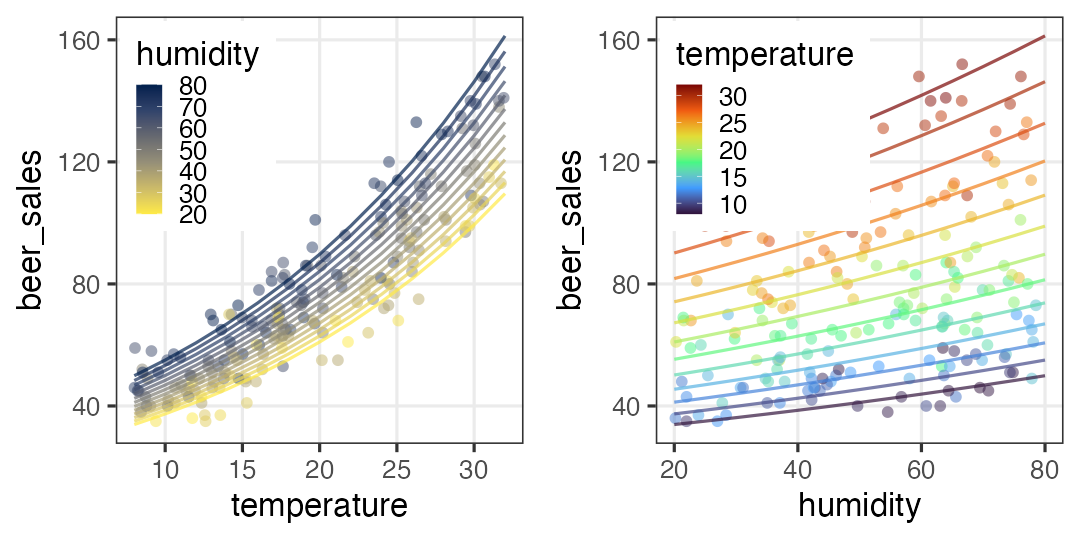
ほかの確率分布とリンク関数を使う例を見てみよう。
ロジスティック回帰
- 確率分布: 二項分布
- リンク関数: $\operatorname{logit}(p) = \log \frac {p} {1 - p}$
何かの成否に対する何かの因子の影響、とか
客$n_i$人中$y_i$人がビールを注文。
その日$i$の気温$x_i$によって割合が変化。
\[\begin{split} y_i &\sim \text{Binomial}(n_i,~p_i) \\ \operatorname{logit}(p_i) &= \beta_0 + \beta_1 x_i \\ p_i &= \frac 1 {1 + e^{-(\beta_0 + \beta_1 x_i)}} \end{split}\]
ロジスティック関数↑
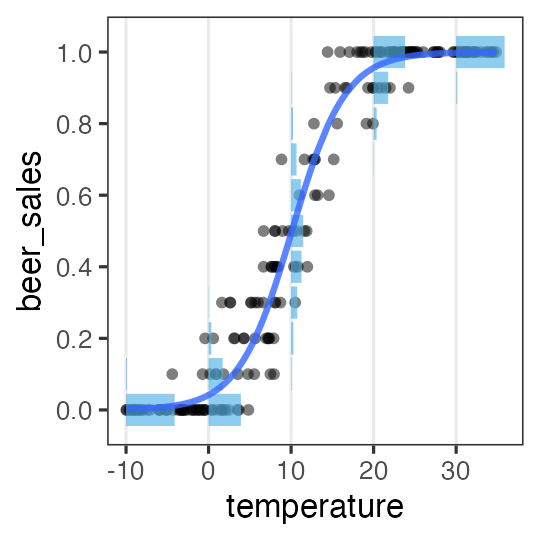
ロジスティック回帰 (狭義)
- 確率分布: ベルヌーイ分布 ($n = 1$ の二項分布)
- リンク関数: $\operatorname{logit}(p) = \log \frac {p} {1 - p}$
何かの成否に対する何かの因子の影響、とか
風が吹けば桶屋が儲かる。
\[\begin{split} y_i &\sim \text{Bernoulli}(p_i) \\ &= \text{Binomial}(1,~p_i) \\ \operatorname{logit}(p_i) &= \beta_0 + \beta_1 x_i \\ p_i &= \frac 1 {1 + e^{-(\beta_0 + \beta_1 x_i)}} \end{split}\]
ロジスティック関数↑
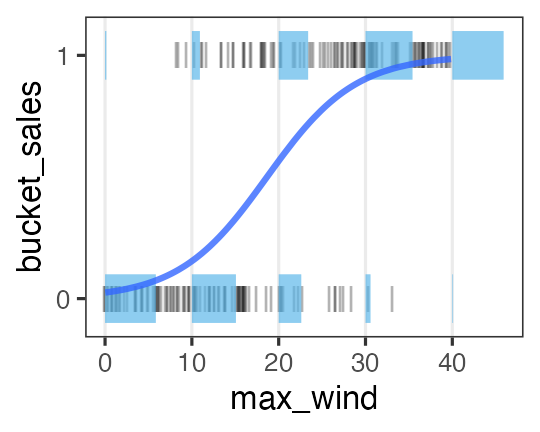
一般線形モデル (“化”無し) はGLMの一種
- 確率分布: 正規分布
- リンク関数: 恒等関数(なにもせずそのまま)
\[\begin{split} y_i &\sim \mathcal{N}(\mu_i,~\sigma^2) \\ \operatorname{identity}(\mu_i) &= \beta_0 + \beta_1 x_i \end{split}\]
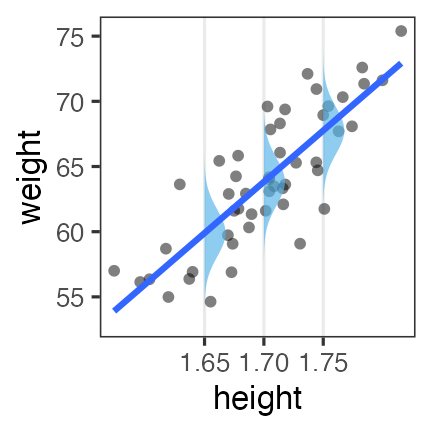
最小二乗法の直線あてはめと結果的に同じになる。
単回帰・重回帰と言ったとき一般線形モデルを前提とする人もいる。
分散分析 (Analysis of variance, ANOVA) as GLM
質的な説明変数を持つ正規分布・恒等リンクのGLM、と解釈可能。
指示変数 (0 or 1) に変換してから重回帰する。
| 天気 | → | $x_1$ ☀️ 晴れ | $x_2$ ☔️ 雨 |
|---|---|---|---|
| ☁️ くもり | 0 | 0 | |
| ☀️ 晴れ | 1 | 0 | |
| ☔️ 雨 | 0 | 1 |
\[\begin{split} y_i &\sim \mathcal{N}(\mu_i,\sigma^2) \\ \mu_i &= \beta_0 + \beta_1 x_{1i} + \beta_2 x_{2i} \end{split}\]
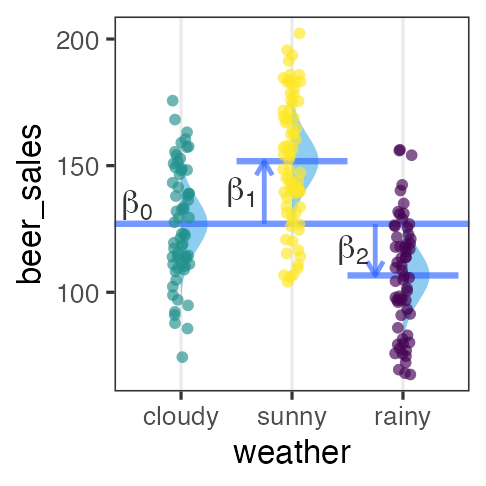
くもり☁️ $\beta_0$ を基準に、晴れの効果☀️ $\beta_1$ と雨の効果☔️ $\beta_2$ が求まる。
GLMなら確率分布・リンク関数を変えてもっと柔軟にモデリングできる。
共分散分析 (Analysis of covariance, ANCOVA) as GLM
質的変数と量的変数を両方含むGLM、と解釈可能。
正規分布・等分散・恒等リンクなどが仮定される。
| 天気 | → | $x_1$ ☀️ 晴れ | $x_2$ ☔️ 雨 |
|---|---|---|---|
| ☁️ くもり | 0 | 0 | |
| ☀️ 晴れ | 1 | 0 | |
| ☔️ 雨 | 0 | 1 |
\[\begin{split} y_i &\sim \mathcal{N}(\mu_i,\sigma^2) \\ \mu_i &= \beta_0 + \beta_1 x_{1i} + \beta_2 x_{2i} + \beta_3 x_{3i} \end{split}\]
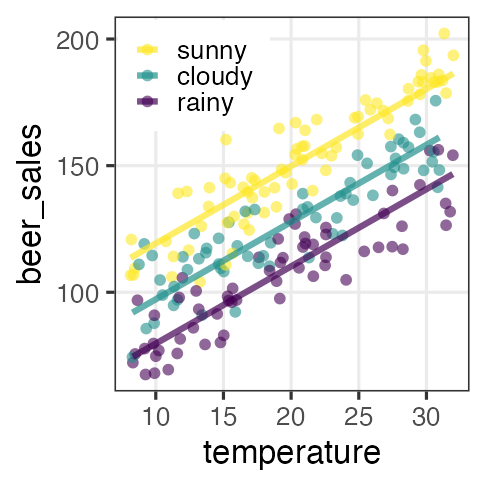
GLMなら確率分布・リンク関数を変えてもっと柔軟にモデリングできる。
一般化線形モデル(GLM)ふりかえり
確率分布・リンク関数を変えて柔軟にモデリングできる。
特定の組み合わせには名前がある。
| 名前 | 確率分布 | リンク関数 | 説明変数 |
|---|---|---|---|
| ポアソン回帰 | ポアソン分布 | log | |
| ロジスティック回帰 | 二項分布 | logit | |
| 一般線形回帰 | 正規分布 | 恒等 | |
| 分散分析 | 正規分布 | 恒等 | 質的変数 |
| 共分散分析 | 正規分布 | 恒等 | 質的変数+量的変数 |
統計モデリングの教科書決定版: 久保先生の緑本
ちょっとずつ線形モデルを発展させていく。
線形モデル LM (単純な直線あてはめ)
↓ いろんな確率分布を扱いたい
一般化線形モデル GLM
↓ 個体差などの変量効果を扱いたい
一般化線形混合モデル GLMM
↓ もっと自由なモデリングを!
階層ベイズモデル HBM
最小二乗法
最尤推定法
MCMC
今回はごく一部のみチラ見せ。理解を目指さなくていいです。
参考文献
- データ解析のための統計モデリング入門 久保拓弥 2012
- StanとRでベイズ統計モデリング 松浦健太郎 2016
- RとStanではじめる ベイズ統計モデリングによるデータ分析入門 馬場真哉 2019
- データ分析のための数理モデル入門 江崎貴裕 2020
- 分析者のためのデータ解釈学入門 江崎貴裕 2020
- 統計学を哲学する 大塚淳 2020
- 科学とモデル—シミュレーションの哲学 入門 Michael Weisberg 2017
(原著: Simulation and Similarity 2013)