統計モデリング入門 2023 岩手連大
(Graduate School of Life Sciences, Tohoku University)
https://heavywatal.github.io/slides/iwate2023stats/
ちょっとずつ線形モデルを発展させていく
線形モデル LM (単純な直線あてはめ)
↓ いろんな確率分布を扱いたい
一般化線形モデル GLM
↓ 個体差などの変量効果を扱いたい
一般化線形混合モデル GLMM
↓ もっと自由なモデリングを!
階層ベイズモデル HBM
「データ解析のための統計モデリング入門」久保拓弥 2012 より改変
直線あてはめ: 統計モデルの出発点
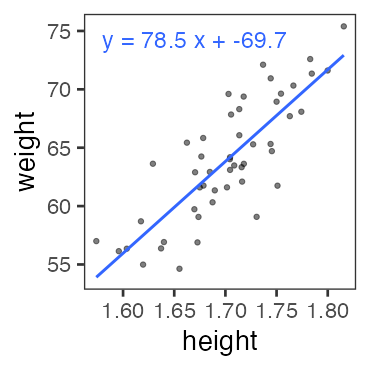
- 身長が高いほど体重も重い。いい感じ。
(説明のために作った架空のデータ。今後もほぼそうです)
回帰モデルの2段階
-
Define a family of models: だいたいどんな形か、式をたてる
- 直線: $y = a_1 + a_2 x$
- 対数: $\log(y) = a_1 + a_2 x$
- 二次曲線: $y = a_1 + a_2 x^2$
-
Generate a fitted model: データに合うようにパラメータを調整
- $y = 3x + 7$
- $y = 9x^2$
たぶん身長が高いほど体重も重い
なんとなく $y = a x + b$ でいい線が引けそう
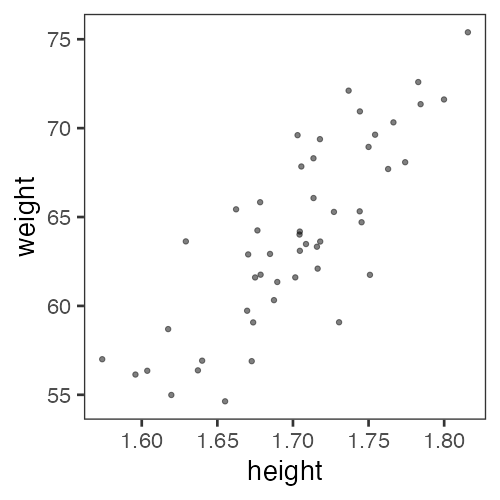
たぶん身長が高いほど体重も重い
なんとなく $y = a x + b$ でいい線が引けそう
じゃあ傾き a と切片 b、どう決める?
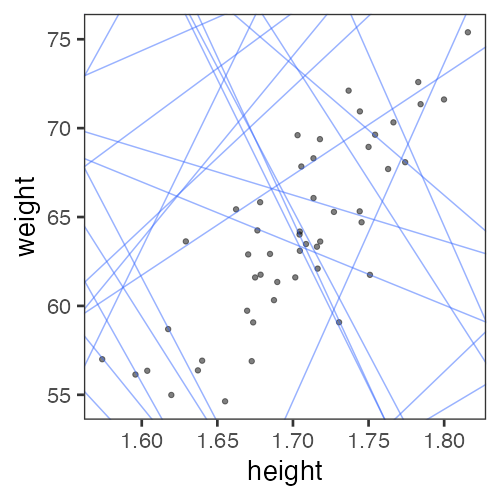
最小二乗法 (Ordinary Least Square: OLS)
回帰直線からの残差平方和(RSS)を最小化する。
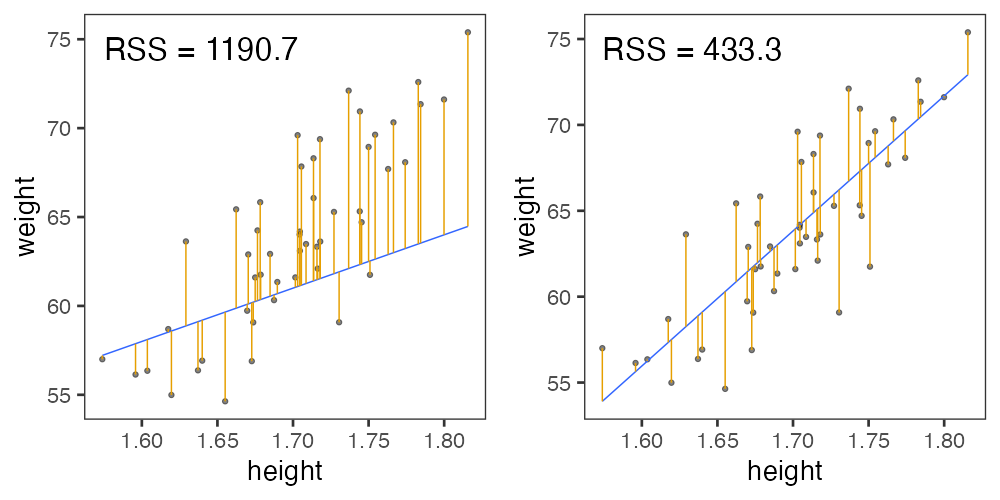
残差平方和(RSS)が最小となるパラメータを探せ
ランダムに試してみて、上位のものを採用。
この程度の試行回数では足りなそう。
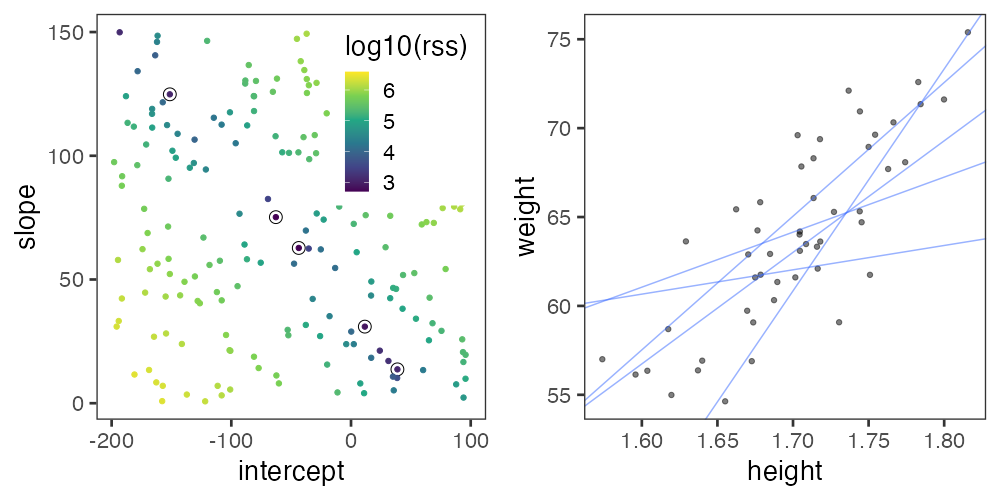
残差平方和(RSS)が最小となるパラメータを探せ
グリッドサーチ: パラメータ空間の一定範囲内を均等に試す。
さっきのランダムよりはちょっとマシか。
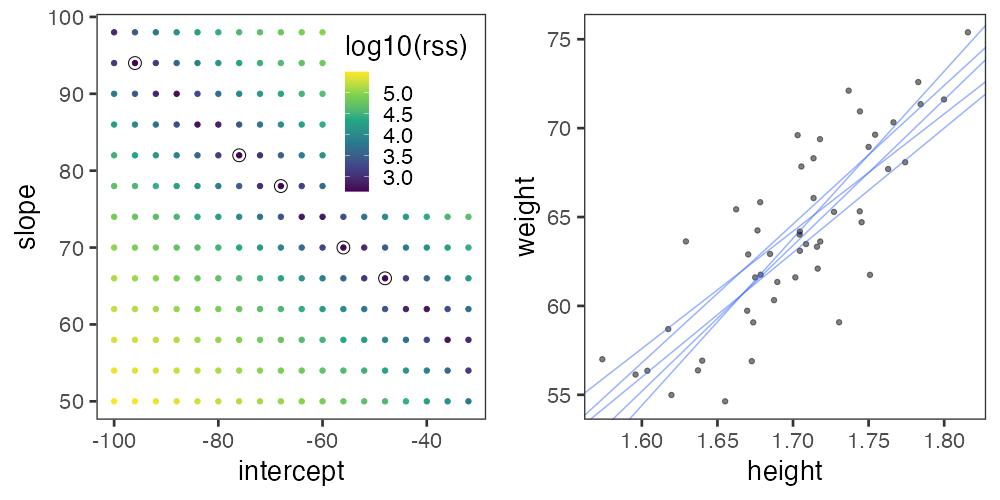
こうした最適化の手法はいろいろあるけど、ここでは扱わない。
これくらいなら一瞬で計算してもらえる
par_init = c(intercept = 0, slope = 0)
result = optim(par_init, fn = rss_weight, data = df_weight)
result$par
intercept slope
-69.68394 78.53490

上記コードは最適化一般の書き方。
回帰が目的なら次ページのようにするのが楽 →
lm() で直線あてはめしてみる
架空のデータを作る(乱数生成については後述):
n = 50
df_weight = tibble::tibble(
height = rnorm(n, 1.70, 0.05),
bmi = rnorm(n, 22, 1),
weight = bmi * (height**2)
)
データと関係式(Y ~ X の形)を lm() に渡して係数を読む:
fit = lm(data = df_weight, formula = weight ~ height)
coef(fit)
(Intercept) height
-69.85222 78.63444
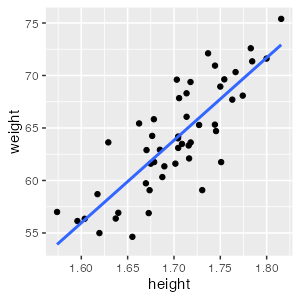
せっかくなので作図もやってみる→
lm() の結果をggplotする
df = modelr::add_predictions(df_weight, fit, type = "response")
head(df, 2L)
height bmi weight pred
1 1.718019 21.55500 63.62151 65.24322
2 1.782862 22.83775 72.59199 70.34213
ggplot(df) +
aes(height, weight) +
geom_point() +
geom_line(aes(y = pred), linewidth = 1, color = "#3366ff")
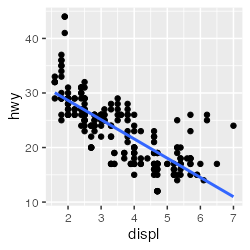
🔰 ほかのデータでも lm() を試してみよう
fit = lm(data = mpg, formula = hwy ~ displ)
coef(fit)
(Intercept) displ
35.697651 -3.530589
mpg_added = modelr::add_predictions(mpg, fit)
ggplot(mpg_added) + aes(displ, hwy) + geom_point() +
geom_line(aes(y = pred), linewidth = 1, color = "#3366ff")
🔰 diamonds などほかのデータでも lm() を試してみよう。
何でもかんでも直線あてはめではよろしくない
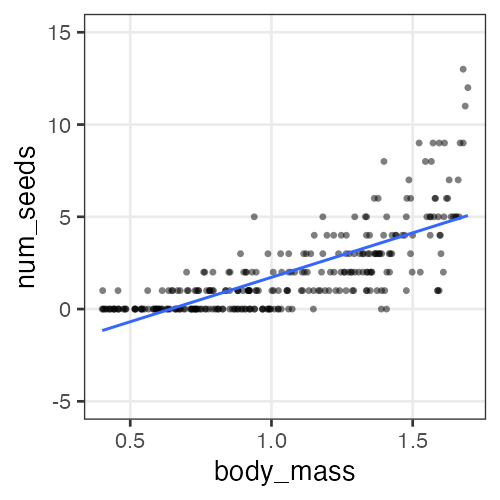
- 観察データは常に正の値なのに予測が負に突入してない?
- 縦軸は整数。しかものばらつきが横軸に応じて変化?
何でもかんでも直線あてはめではよろしくない
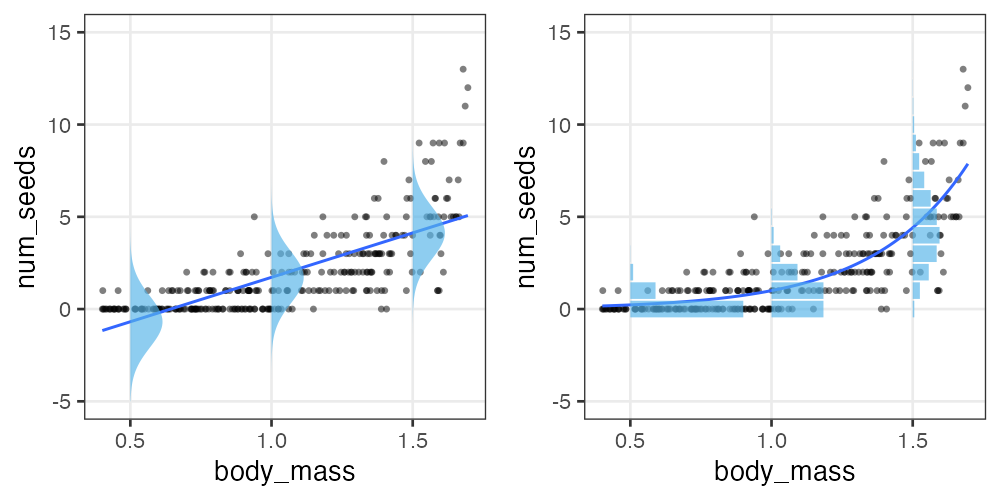
- 観察データは常に正の値なのに予測が負に突入してない?
- 縦軸は整数。しかものばらつきが横軸に応じて変化?
- データに合わせた統計モデルを使うとマシ
ちょっとずつ線形モデルを発展させていく
線形モデル LM (単純な直線あてはめ)
↓ いろんな確率分布を扱いたい
一般化線形モデル GLM
↓ 個体差などの変量効果を扱いたい
一般化線形混合モデル GLMM
↓ もっと自由なモデリングを!
階層ベイズモデル HBM
「データ解析のための統計モデリング入門」久保拓弥 2012 より改変
確率分布
発生する事象(値)と頻度の関係。
手元のデータを数えて作るのが経験分布
e.g., サイコロを12回投げた結果、学生1000人の身長
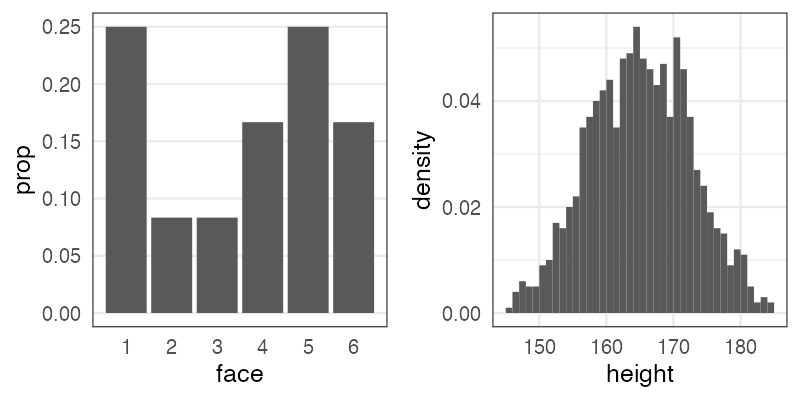
一方、少数のパラメータと数式で作るのが理論分布。
(こちらを単に「確率分布」と呼ぶことが多い印象)
確率変数$X$はパラメータ$\theta$の確率分布$f$に従う…?
$X \sim f(\theta)$
e.g.,
コインを3枚投げたうち表の出る枚数 $X$ は二項分布に従う。
$X \sim \text{Binomial}(n = 3, p = 0.5)$
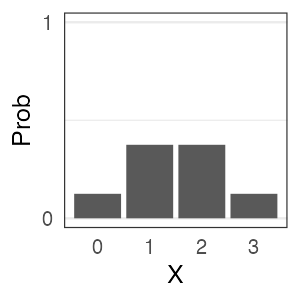
一緒に実験してみよう。
試行を繰り返して記録してみる
コインを3枚投げたうち表の出た枚数 $X$
試行1: 表 裏 表 → $X = 2$
試行2: 裏 裏 裏 → $X = 0$
試行3: 表 裏 裏 → $X = 1$ 続けて $2, 1, 3, 0, 2, \ldots$
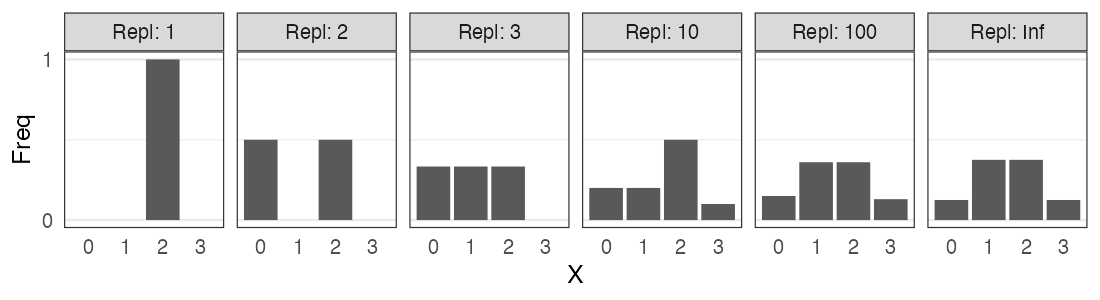
0と3はレア。1と2が3倍ほど出やすいらしい。
コイントスしなくても $X$ らしきものを生成できる
- コインを3枚投げたうち表の出る枚数 $X$
- $n = 3, p = 0.5$ の二項分布からサンプルする乱数 $X$

↓ サンプル
{2, 0, 1, 2, 1, 3, 0, 2, …}
これらはとてもよく似ているので
「コインをn枚投げたうち表の出る枚数は二項分布に従う」
みたいな言い方をする。逆に言うと
「二項分布とはn回試行のうちの成功回数を確率変数とする分布」
のように理解できる。
統計モデリングの一環とも捉えられる
コイン3枚投げを繰り返して得たデータ {2, 0, 1, 2, 1, 3, 0, 2, …}
↓ たった2つのパラメータで記述。情報を圧縮。
$n = 3, p = 0.5$ の二項分布で説明・再現できるぞ

こういうふうに現象と対応した確率分布、ほかにもある?
有名な確率分布、それに「従う」もの
- 離散一様分布
- コインの表裏、サイコロの出目1–6
- 負の二項分布 (幾何分布 if n = 1)
- 成功率pの試行がn回成功するまでの失敗回数
- 二項分布
- 成功率p、試行回数nのうちの成功回数
- ポアソン分布
- 単位時間あたり平均$\lambda$回起こる事象の発生回数
- ガンマ分布 (指数分布 if k = 1)
- ポアソン過程でk回起こるまでの待ち時間
- 正規分布
- 確率変数の和、平均値など。
離散一様分布
同じ確率で起こるn通りの事象のうちXが起こる確率
e.g., コインの表裏、サイコロの出目1–6
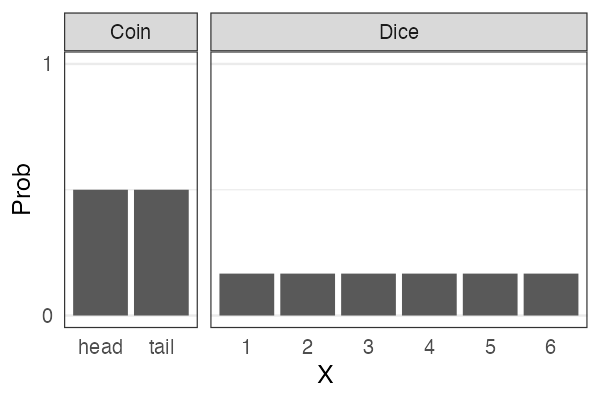
🔰 一様分布になりそうな例を考えてみよう
幾何分布 $~\text{Geom}(p)$
成功率pの試行が初めて成功するまでの失敗回数
e.g., コイントスで表が出るまでに何回裏が出るか
\[ \Pr(X = k \mid p) = p (1 - p)^k \]
「初めて成功するまでの試行回数」とする定義もある。
🔰 幾何分布になりそうな例を考えてみよう
負の二項分布 $~\text{NB}(n, p)$
成功率pの試行がn回成功するまでの失敗回数X。 n = 1 のとき幾何分布と一致。
\[ \Pr(X = k \mid n,~p) = \binom {n + k - 1} k p^n (1 - p)^k \]
失敗回数ではなく試行回数を変数とする定義もある。
🔰 負の二項分布になりそうな例を考えてみよう
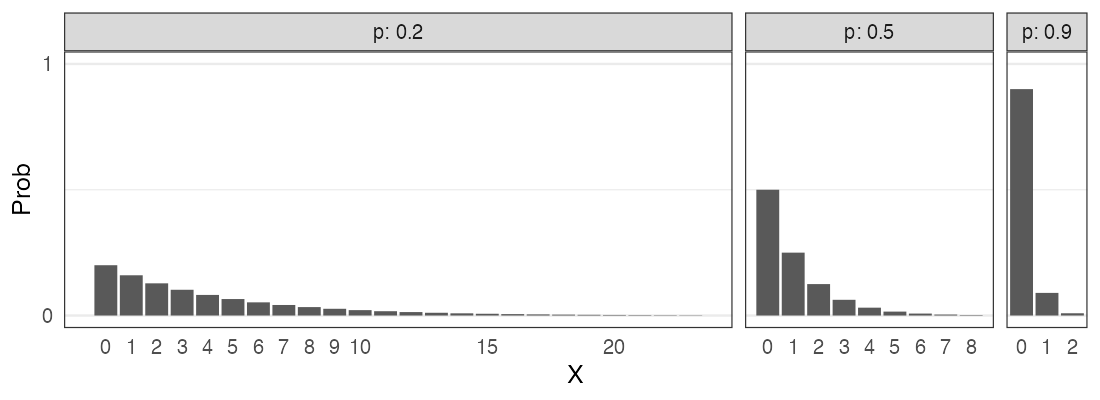
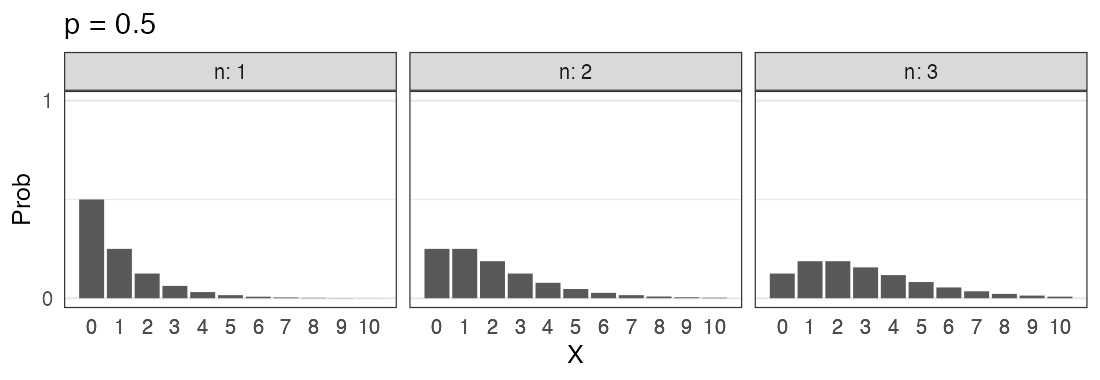
二項分布 $~\text{Binomial}(n,~p)$
確率$p$で当たるクジを$n$回引いてX回当たる確率。平均は$np$。
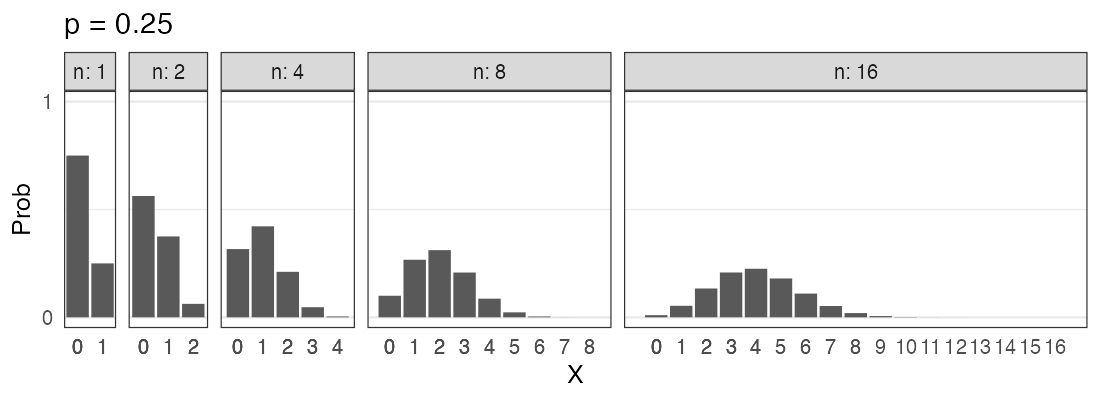
\[ \Pr(X = k \mid n,~p) = \binom n k p^k (1 - p)^{n - k} \]
🔰 二項分布になりそうな例を考えてみよう
ポアソン分布 $~\text{Poisson}(\lambda)$
平均$\lambda$で単位時間(空間)あたりに発生する事象の回数。
e.g., 1時間あたりのメッセージ受信件数、メッシュ区画内の生物個体数
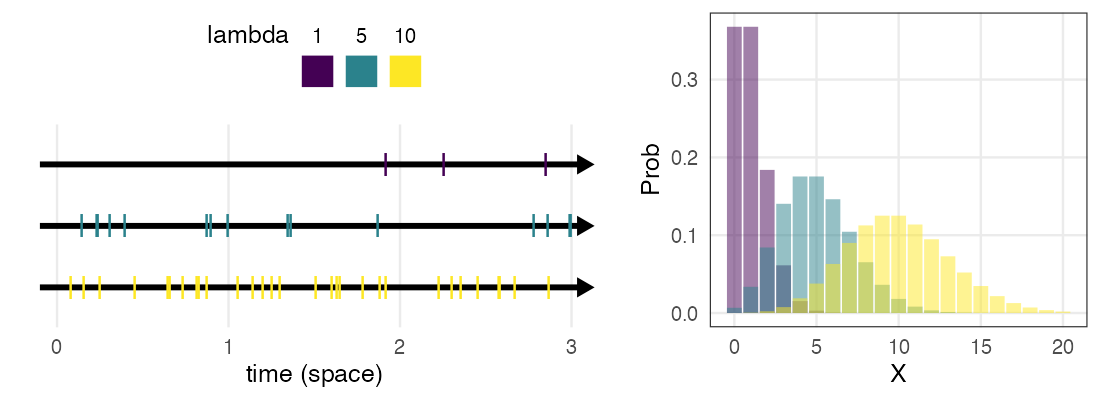
\[ \Pr(X = k \mid \lambda) = \frac {\lambda^k e^{-\lambda}} {k!} \]
二項分布の極限 $(\lambda = np;~n \to \infty;~p \to 0)$。
めったに起きないことを何回も試行するような感じ。
指数分布 $~\text{Exp}(\lambda)$
ポアソン過程の事象の発生間隔。平均は $1 / \lambda$ 。
e.g., メッセージの受信間隔、道路沿いに落ちてる手袋の間隔
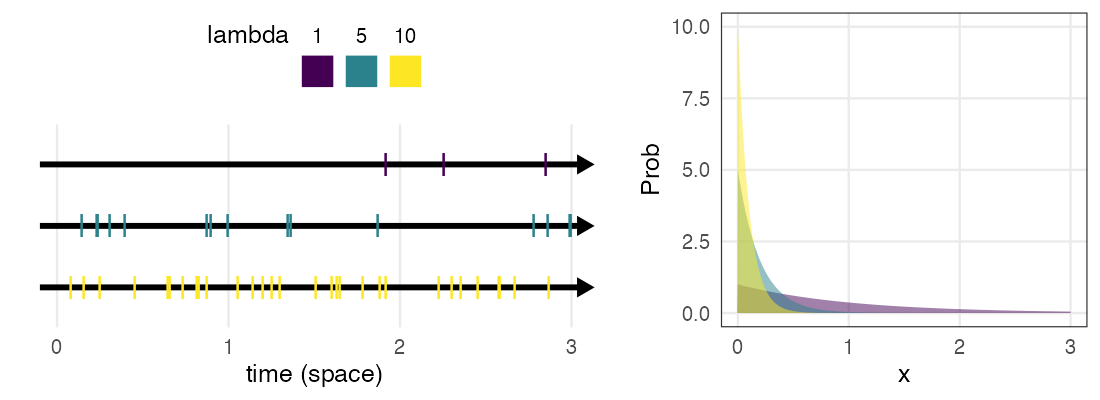
\[ \Pr(x \mid \lambda) = \lambda e^{-\lambda x} \]
幾何分布の連続値版。
🔰 ポアソン分布・指数分布になりそうな例を考えてみよう
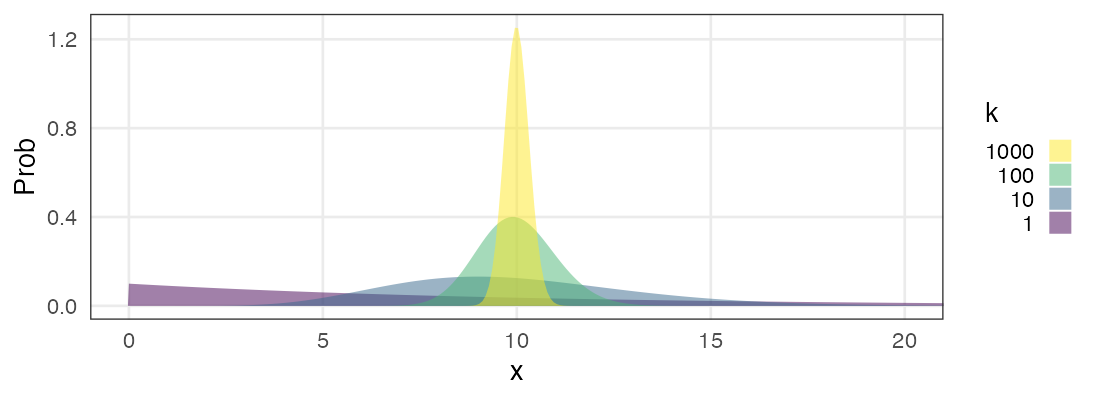
ガンマ分布 $~\text{Gamma}(k,~\lambda)$
ポアソン過程の事象k回発生までの待ち時間
e.g., メッセージを2つ受信するまでの待ち時間
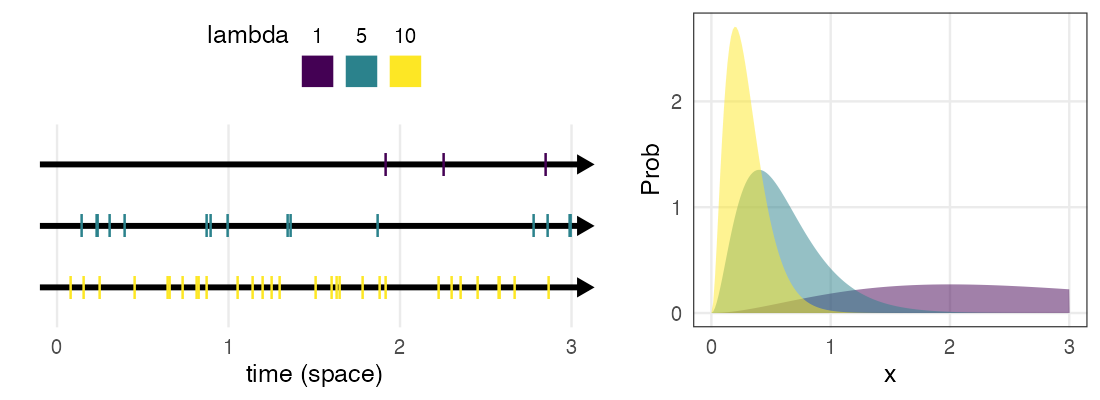
\[ \Pr(x \mid k,~\lambda) = \frac {\lambda^k x^{k - 1} e^{-\lambda x}} {\Gamma(k)} \]
指数分布をkのぶん右に膨らませた感じ。
shapeパラメータ $k = 1$ のとき指数分布と一致。
正規分布 $~\mathcal{N}(\mu,~\sigma)$
平均 $\mu$、標準偏差 $\sigma$ の美しい分布。よく登場する。
e.g., $\mu = 50, ~\sigma = 10$ (濃い灰色にデータの95%, 99%が含まれる):
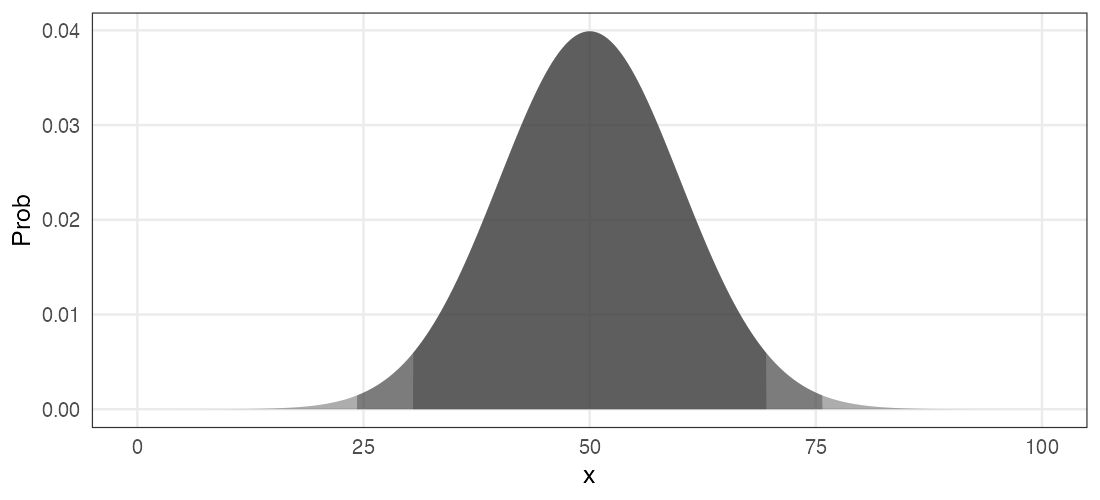
\[ \Pr(x \mid \mu,~\sigma) = \frac 1 {\sqrt{2 \pi \sigma^2}} \exp \left(\frac {-(x - \mu)^2} {2\sigma^2} \right) \]
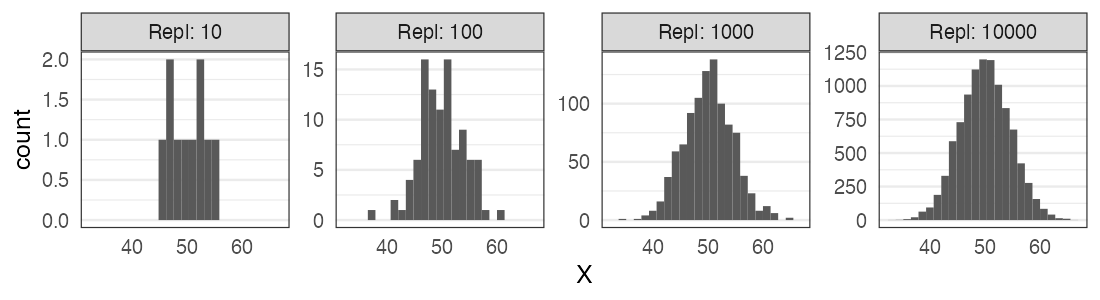
正規分布に近づくものがいろいろある
標本平均の反復(中心極限定理); e.g., 一様分布 [0, 100) から40サンプル
大きい$n$の二項分布
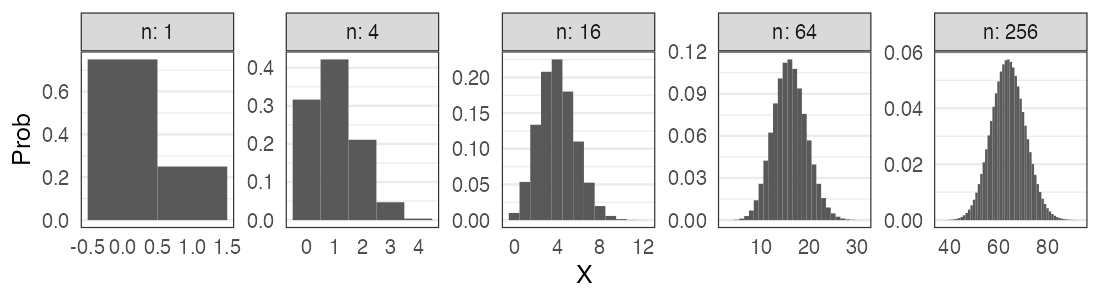
正規分布に近づくものがいろいろある
大きい$\lambda$のポアソン分布
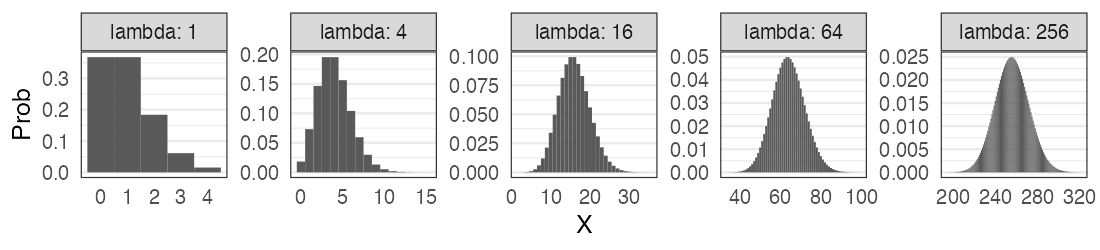
平均値固定なら$k$が大きくなるほど左右対称に尖るガンマ分布
有名な確率分布対応関係ふりかえり
- 離散一様分布
- コインの表裏、サイコロの出目1–6
- 負の二項分布 (幾何分布 if n = 1)
- 成功率pの試行がn回成功するまでの失敗回数
- 二項分布
- 成功率p、試行回数nのうちの成功回数
- ポアソン分布
- 単位時間あたり平均$\lambda$回起こる事象の発生回数
- ガンマ分布 (指数分布 if k = 1)
- ポアソン過程でk回起こるまでの待ち時間
- 正規分布
- 確率変数の和、平均値。使い勝手が良く、よく登場する。
現実には、確率分布に「従わない」ことが多い
植物100個体から8個ずつ種子を取って植えたら全体で半分ちょい発芽。
親1個体あたりの生存数はn=8の二項分布になるはずだけど、
極端な値(全部死亡、全部生存)が多かった。
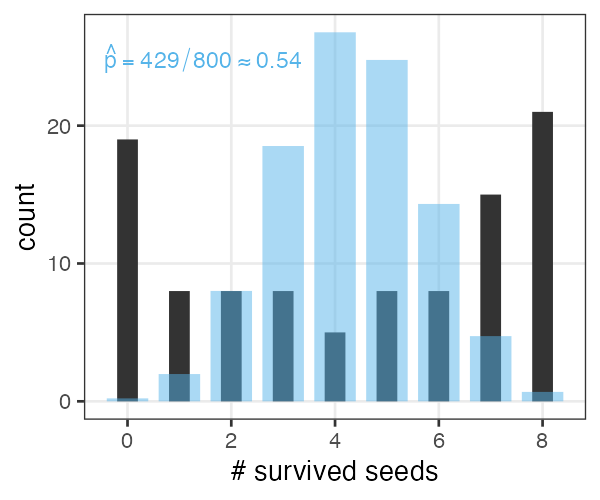
「それはなぜ?」と考えて要因を探るのも統計モデリングの仕事。
「普通はこれに従うはず」を理解してこそできる思考。
疑似乱数生成器 Pseudo Random Number Generator
コンピューター上でランダムっぽい数値を出力する装置。
実際には決定論的に計算されているので、
シード(出発点)と呼び出し回数が同じなら出る数も同じになる。
set.seed(42)
runif(3L)
# 0.9148060 0.9370754 0.2861395
runif(3L)
# 0.8304476 0.6417455 0.5190959
set.seed(42)
runif(6L)
# 0.9148060 0.9370754 0.2861395 0.8304476 0.6417455 0.5190959
シードに適当な固定値を与えておくことで再現性を保てる。
ただし「このシードじゃないと良い結果が出ない」はダメ。
さまざまな「分布に従う」乱数を生成することもできる。
いろんな乱数を生成・可視化して感覚を掴もう
n = 100
x = sample.int(6, n, replace = TRUE)
x = runif(n, min = 0, max = 1)
x = rgeom(n, prob = 0.5)
x = rbinom(n, size = 3, prob = 0.5)
x = rpois(n, lambda = 10)
x = rnorm(n, mean = 50, sd = 10)
print(x)
p1 = ggplot(data.frame(x)) + aes(x)
p1 + geom_histogram() # for continuous values
p1 + geom_bar() # for discrete values
🔰 小さい n から徐々に大きくして変化を確認しよう。
🔰 ほかのオプションもいろいろ変えて変化を確認しよう。
🔰 1%の当たりを狙って10連ガチャを回す人が100万人いたら、
全部はずれ、1つ当たり、2つ当たり… の人はどれくらいいるか?
いろいろ試した結果をとっておきたい
スクリプト.Rさえ保存しておけばいつでも実行できるけど… 面倒
ggsave() で画像を書き出しておけるけど… どのコードの結果か分からない
→ スクリプトと実行結果を一緒に見渡せる形式が欲しい。
3 * 14
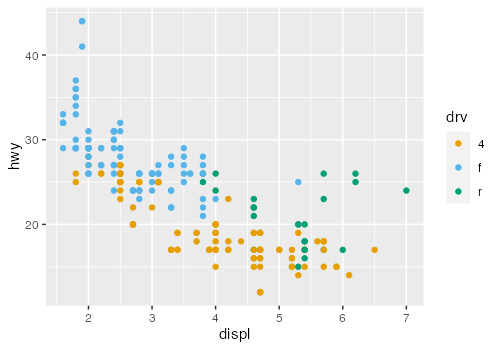
ggplot(mpg) + aes(displ, hwy) + geom_point(aes(color = drv))
[1] 42
Quarto Document として研究ノートを作る

プログラミングからレポート作成まで一元管理できて楽ちん。
- 本文とRコードを含むテキストファイル.qmdを作る。
- HTML, PDFなどリッチな形式に変換して読む。
- コードだけでなく実行結果の図や表も埋め込める。

- Quarto Markdown (
.qmd) - RやPythonのコードと図表を埋め込めるMarkdown亜種。
- Quarto登場前にほぼR専用だった
.Rmdと使い勝手は同じ。 - Markdown (
.md) - 最もよく普及している軽量マークアップ言語のひとつ。
- 微妙に異なる方言がある。qmdで使うのは Pandoc Markdown 。
🔰 どんなものが作れるのか 作成例ギャラリー を見てみよう。
マークアップ言語
文書の構造や視覚的修飾を記述するための言語。
e.g., HTML+CSS, XML, LaTeX
<h3>見出し3</h3>
<p>ここは段落。
<em>強調(italic)</em>、
<strong>強い強調(bold)</strong>、
<a href="https://www.lifesci.tohoku.ac.jp/">リンク</a>とか。
</p>
見出し3
ここは段落。 強調(italic)、 強い強調(bold)、 リンクとか。
表現力豊かで強力だが人間が読み書きするには複雑すぎ、機械寄り。
🔰 好きなウェブサイトのソースコード(HTML)を見てみよう。
軽量マークアップ言語
マークアップ言語の中でも人間が読み書きしやすいもの。
e.g., Markdown, reStructuredText, 各種Wiki記法など
### 見出し3
ここは段落。
*強調(italic)*、
**強い強調(bold)**、
[リンク](https://www.lifesci.tohoku.ac.jp/)とか。
見出し3
ここは段落。 強調(italic)、 強い強調(bold)、 リンクとか。
Quartoする環境は既に整っているはず
- R (≥ 4.3.1): 最新版 – 0.1 くらいまでが許容範囲
- RStudio (≥ 2023.06.0+421): Quarto CLI を同梱
- tidyverse (≥ 2.0.0): 次の2つを自動インストール
- rmarkdown (≥ 2.22)
- knitr (≥ 1.43)
(示してあるバージョンは最低要件ではなく私の現在の環境の)
- Quarto CLI: 最新版を求めるなら手動で入れる。
install.packages("quarto"): 多くの人には不要。 Quarto CLIをRコマンドで呼べるようにするだけ。- pandoc: Quarto CLI に同梱。 手動で最新版を入れてもRStudio+Quartoがそれを使うかは不明。
Markdown記法で書いてみよう
- RStudio > New File > Markdown File
- “markdown 記法"とかで検索しつつ何か書く。
- 見出し1, 2, 3
- 箇条書き (番号あり・なし)
- インラインコード、コードブロック
- Previewボタンで確認
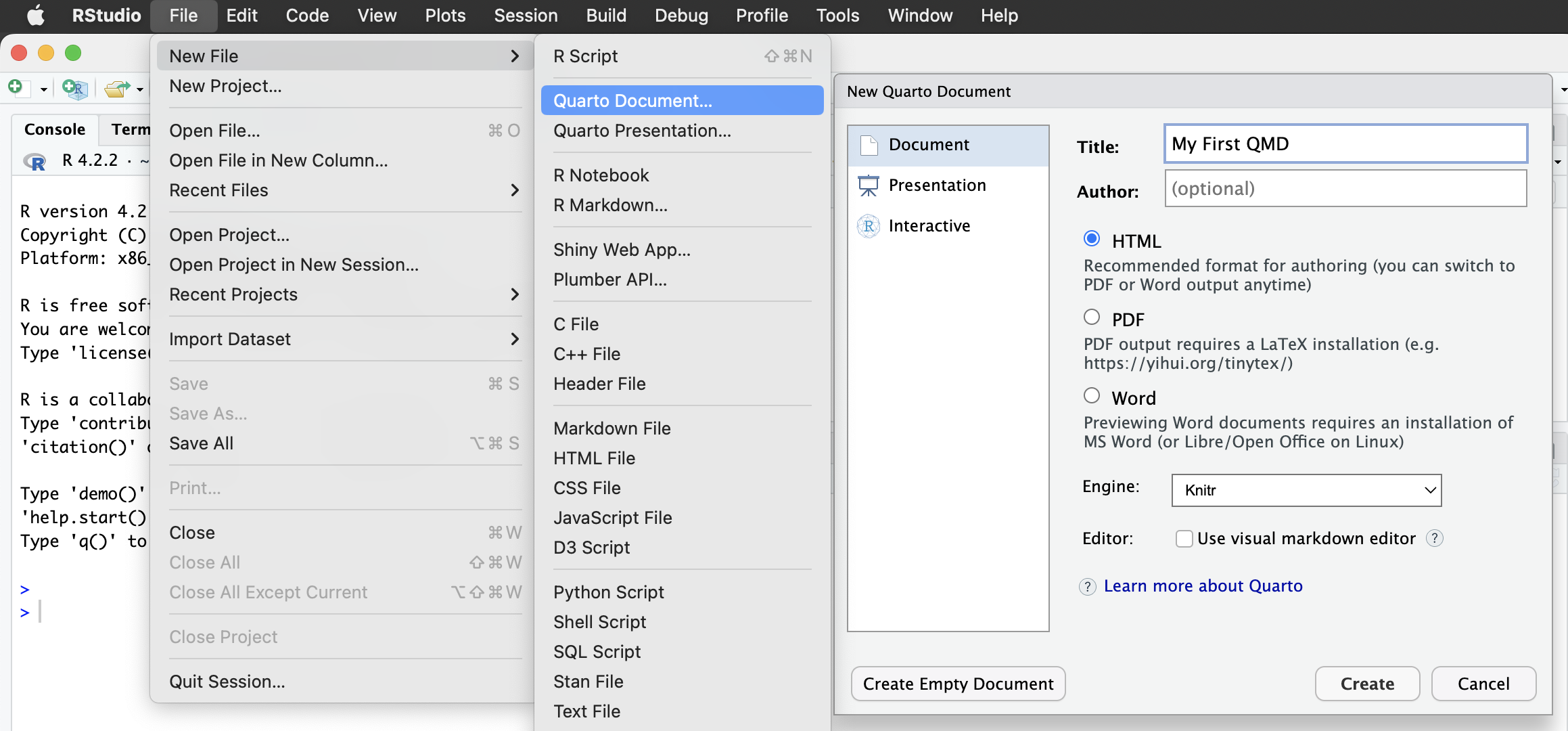
Quarto Document を作ってみよう
RStudio > New File > Quarto Document…
(DocumentとHTMLを選択し、)タイトルと著者を埋めて、OK。
普通のmdには無いqmdの特徴
- ヘッダー
- 最上部の
---で挟まれた部分。 文書全体に関わるメタデータを入力。 - オプションは出力形式によって異なる。
e.g.,
html - R code chunk
```{r}のように始まるブロック。- コードの実行結果を最終産物に埋め込める。
- オプションがいろいろある。e.g.,
echo: false: コードを非表示。結果は表示。eval: false: コードを実行せず表示だけ。include: false: コードも結果も表示せず、実行だけする。fig.width: 7, fig.height: 7: 図の大きさを制御。
まあ細かいことは必要になってから調べるとして…
qmdをHTMLに変換してみよう
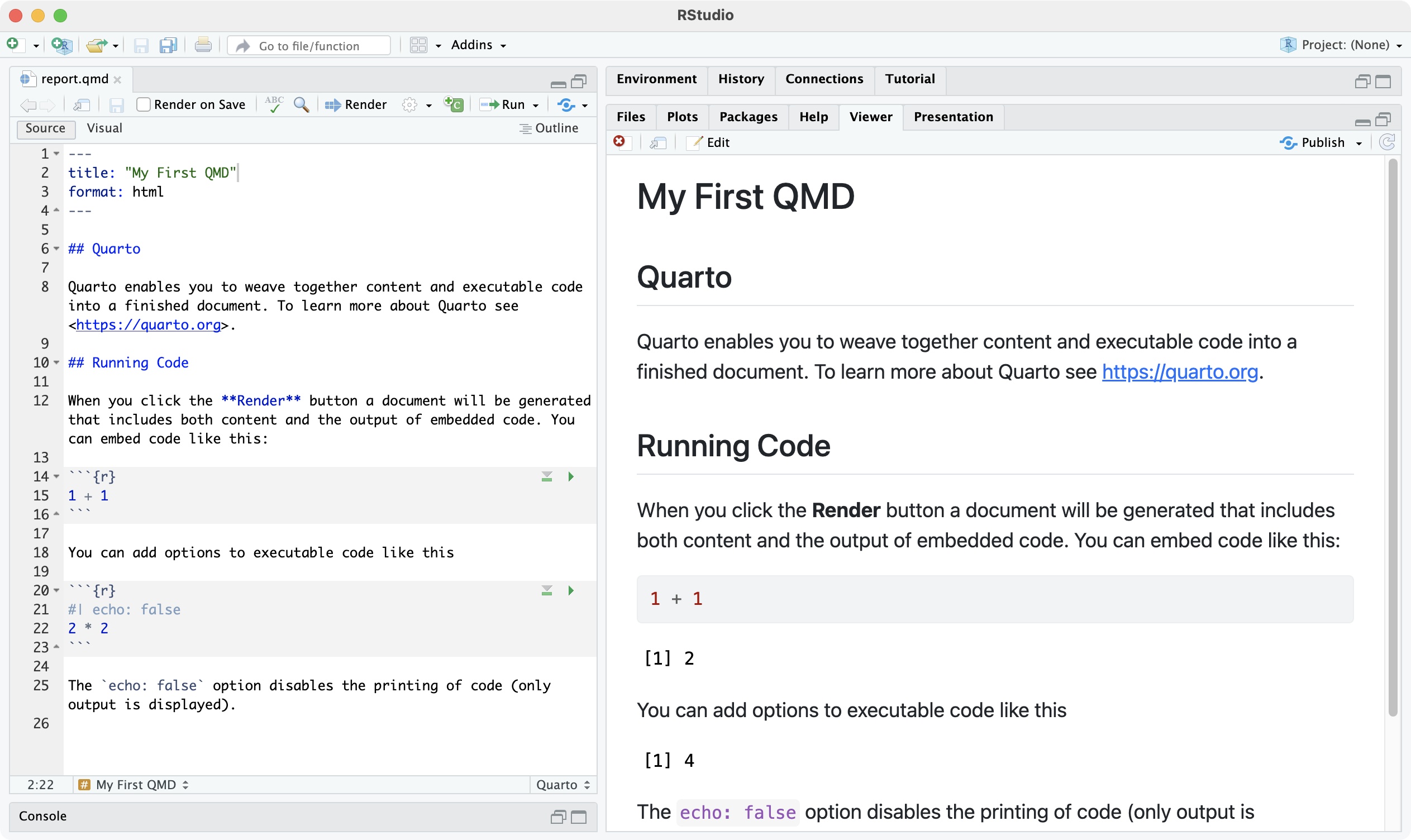
qmdをHTMLに変換してみよう
- ソースコードに名前をつけて保存 commands
e.g.,report.qmd - ⚙️ ボタンから “Preview in Viewer Pane” を選択。
- →Render を押す。
- 埋め込まれたRコードが実行される。
- 実行結果を含むMarkdownが作られる。
- MarkdownからHTMLに変換される。 e.g.,
report.html - プレビューが自動的に開く。
🔰 編集 → Render を繰り返して変化を確認しよう
🔰 疑似乱数生成をいろいろ試した研究ノートを作ろう
さっきはこんな汚いスクリプトだった:
n = 100
x = sample.int(6, n, replace = TRUE)
x = runif(n, min = 0, max = 1)
x = rgeom(n, prob = 0.5)
x = rbinom(n, size = 3, prob = 0.5)
x = rpois(n, lambda = 10)
x = rnorm(n, mean = 50, sd = 10)
print(x)
p1 = ggplot(data.frame(x)) + aes(x)
p1 + geom_histogram() # for continuous values
p1 + geom_bar() # for discrete values
- ひとつの分布につきひとつの図を描くqmdに書き換える。
- コードチャンクを分けたり見出しを付けたりして整理する。
- パラメータをいろいろ変えた結果も加えていく。
本講義のお品書き

久保先生の"緑本"こと
「データ解析のための統計モデリング入門」
をベースに回帰分析の概要を紹介。
- イントロ
- Rの基礎を駆け足で
- 統計モデルの基本
- 直線回帰
- 確率変数・確率分布 👈 ここまでやった
- 尤度・最尤推定
- 一般化線形モデル、混合モデル
- ベイズ統計、階層ベイズモデル
回帰のキモは線ではなく分布
参考文献
- データ解析のための統計モデリング入門 久保拓弥 2012
- StanとRでベイズ統計モデリング 松浦健太郎 2016
- RとStanではじめる ベイズ統計モデリングによるデータ分析入門 馬場真哉 2019
- データ分析のための数理モデル入門 江崎貴裕 2020
- 分析者のためのデータ解釈学入門 江崎貴裕 2020
- 統計学を哲学する 大塚淳 2020