進化学実習 2022 牧野研
5. データ内容の処理: 数値、文字列、日時など。
前回までのまとめ
✅ Rの基礎
- 調べ方さえわかれば、全部覚えなくても大丈夫
- エラーは日常茶飯事。落ち着いて読み取ろう
- まずRスクリプトに書いてから、コンソールで実行
- 便利なパッケージを使おう
✅ データ解析全体の流れ。可視化だいじ
✅ 一貫性のある文法で合理的に描けるggplot2
✅ 使える整然データにするための前処理がたいへん
データ解析のおおまかな流れ
- コンピュータ環境の整備
- データの取得、読み込み
- 探索的データ解析
- 前処理、加工 (地味。意外と重い) 👈 本実習の主題
- 可視化、仮説生成 (派手!だいじ!)
- 統計解析、仮説検証 (みんな勉強したがる)
- 報告、発表
前処理は大きく2つに分けられる


- データ構造を対象とする処理 — 第3, 4回
- 使いたい部分だけ抽出 —
select(),filter() - グループごとに特徴を要約 —
group_by(),summarize() - 何かの順に並べ替え —
arrange() - 異なるテーブルの結合 —
*_join() - 変形: 縦長 ↔ 横広 —
pivot_longer(),pivot_wider()
- 使いたい部分だけ抽出 —
- データ内容を対象とする処理 👈 第5回 本日の話題
- 数値の変換: 対数、正規化
- 外れ値・欠損値への対処
- 型変換: 連続変数、カテゴリカル変数、指示変数、因子、日時
- 文字列処理: 正規表現によるパターンマッチ
tidyverse: データ科学のためのパッケージ群
- 統一的な使い勝手
- シンプルな関数を繋げて使うデザイン
# install.packages("tidyverse")
library(tidyverse) # パッケージ読み込み
── Attaching packages ─────────────────── tidyverse 1.3.1 ──
✔ ggplot2 3.3.5 ✔ purrr 0.3.4
✔ tibble 3.1.6 ✔ dplyr 1.0.8
✔ tidyr 1.2.0 ✔ stringr 1.4.0
✔ readr 2.1.2 ✔ forcats 0.5.1
── Conflicts ────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
たまには更新しよう:
update.packages(ask = "no", type = "binary")
# いちいち確認せずにビルド済み安定版を入れるオプション。無くても。
変数/オブジェクトの型 (復習)
vector: 基本型。一次元の配列。 (👈今回の主役)logical: 論理値 (TRUEorFALSE)numeric: 数値 (整数42Lor 実数3.1416)character: 文字列 ("a string")factor: 因子 (文字列っぽいけど微妙に違う)
array: 多次元配列。vector同様、全要素が同じ型。matrix: 行列 = 二次元の配列。
list: 異なる型でも詰め込める太っ腹ベクトル。data.frame: 同じ長さのベクトルを並べた長方形のテーブル。重要。
tibbleとかtbl_dfと呼ばれる亜種もあるけどほぼ同じ。
vector: 一次元の配列 (復習)
1個の値でもベクトル扱い。
ベクトルの各要素に一気に計算を適用できる。
x = c(1, 2, 9) # 長さ3の数値ベクトル
x + x # 同じ長さ同士の計算
[1] 2 4 18
y = 10 # 長さ1の数値ベクトル
x + y # 長さ3 + 長さ1 = 長さ3 (それぞれ足し算)
[1] 11 12 19
sqrt(x) # square root
[1] 1.000000 1.414214 3.000000
数値: numeric型
普通は倍精度浮動小数点型 double として扱われる:
answer = 42
typeof(answer)
[1] "double"
明示的に変換したり末尾にLを付けることで整数扱いもできる:
typeof(as.integer(answer))
[1] "integer"
whoami = 24601L
typeof(whoami)
[1] "integer"
様々な数学関数
ベクトルを受け取り、それぞれの要素に適用
x = c(1, 2, 3)
sqrt(x)
[1] 1.000000 1.414214 1.732051
log(x)
[1] 0.0000000 0.6931472 1.0986123
log10(x)
[1] 0.0000000 0.3010300 0.4771213
exp(x)
[1] 2.718282 7.389056 20.085537
https://stat.ethz.ch/R-manual/R-patched/library/base/html/00Index.html
data.frameは列vectorの集まり
内容を変更する方法はいくつかある。
diamonds の price 列をドルから円に変換する例:
dia = diamonds # 別名コピー
# dollar演算子 $ で指定
dia$price = 105.59 * dia$price
# 名前を [[文字列]] で指定
dia[["price"]] = 105.59 * dia[["price"]]
# dplyr::mutate with pipe
dia = diamonds %>%
mutate(price = 105.59 * price)
1発ならどれでもいい。流れ作業には mutate() が便利。
正規化 (min-max normalization)
最小=0、最大=1、になるように:
normalized_minmax = diamonds %>%
mutate(price = (price - min(price)) / (max(price) - min(price))) %>%
print()
carat cut color clarity depth table price x y z
<dbl> <ord> <ord> <ord> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 0.23 Ideal E SI2 61.5 55 0.000000e+00 3.95 3.98 2.43
2 0.21 Premium E SI1 59.8 61 0.000000e+00 3.89 3.84 2.31
3 0.23 Good E VS1 56.9 65 5.406282e-05 4.05 4.07 2.31
4 0.29 Premium I VS2 62.4 58 4.325026e-04 4.20 4.23 2.63
--
53937 0.72 Good D SI1 63.1 55 1.314267e-01 5.69 5.75 3.61
53938 0.70 Very Good D SI1 62.8 60 1.314267e-01 5.66 5.68 3.56
53939 0.86 Premium H SI2 61.0 58 1.314267e-01 6.15 6.12 3.74
53940 0.75 Ideal D SI2 62.2 55 1.314267e-01 5.83 5.87 3.64
外れ値の影響を大きく受けることに注意。
正規化 (z-score normalization)
平均=0、標準偏差=1、になるように:
normalized_z = diamonds %>%
mutate(price = (price - mean(price)) / sd(price)) %>%
print()
carat cut color clarity depth table price x y z
<dbl> <ord> <ord> <ord> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 0.23 Ideal E SI2 61.5 55 -0.9040868 3.95 3.98 2.43
2 0.21 Premium E SI1 59.8 61 -0.9040868 3.89 3.84 2.31
3 0.23 Good E VS1 56.9 65 -0.9038361 4.05 4.07 2.31
4 0.29 Premium I VS2 62.4 58 -0.9020815 4.20 4.23 2.63
--
53937 0.72 Good D SI1 63.1 55 -0.2947280 5.69 5.75 3.61
53938 0.70 Very Good D SI1 62.8 60 -0.2947280 5.66 5.68 3.56
53939 0.86 Premium H SI2 61.0 58 -0.2947280 6.15 6.12 3.74
53940 0.75 Ideal D SI2 62.2 55 -0.2947280 5.83 5.87 3.64
price = as.vector(scale(price)) でも可能。
scale() はmatrixを返すため as.vector() が必要。
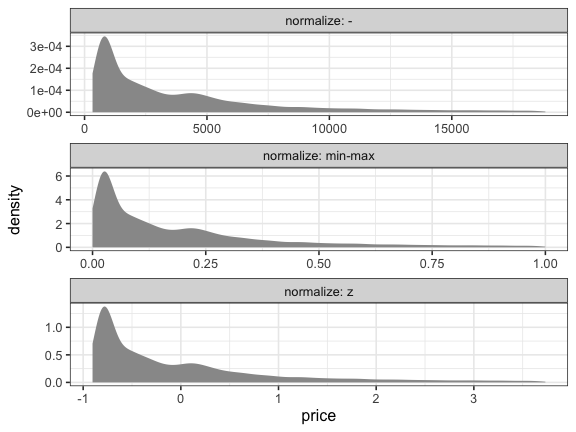
正規化の結果を確認
分布の形は変わらず、範囲が変わる。
z-scoreは正規分布前提。これだけ非対称だと使いにくい。
外れ値の除去
平均値から標準偏差の3倍以上離れているもの($\lvert z \rvert \ge 3$)を取り除く例:
result = diamonds %>%
filter(abs(price - mean(price)) / sd(price) < 3) %>%
print()
carat cut color clarity depth table price x y z
<dbl> <ord> <ord> <ord> <dbl> <dbl> <int> <dbl> <dbl> <dbl>
1 0.23 Ideal E SI2 61.5 55 326 3.95 3.98 2.43
2 0.21 Premium E SI1 59.8 61 326 3.89 3.84 2.31
3 0.23 Good E VS1 56.9 65 327 4.05 4.07 2.31
4 0.29 Premium I VS2 62.4 58 334 4.20 4.23 2.63
--
52731 0.72 Good D SI1 63.1 55 2757 5.69 5.75 3.61
52732 0.70 Very Good D SI1 62.8 60 2757 5.66 5.68 3.56
52733 0.86 Premium H SI2 61.0 58 2757 6.15 6.12 3.74
52734 0.75 Ideal D SI2 62.2 55 2757 5.83 5.87 3.64
唯一の方法ではないし、そもそもやるべきかどうかも要検討
欠損値の除去 tidyr::drop_na()
(指定した列に) NA が含まれてる行を削除する。
df = tibble(x = c(1, 2, NA), y = c("a", NA, "b"))
df %>% drop_na()
x y
<dbl> <chr>
1 1 a
🔰 starwars で身長体重データのある行だけ抽出してみよう
name height mass hair_color skin_color eye_color birth_year sex gender homeworld species films vehicles starships
<chr> <int> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr> <chr> <chr> <list> <list> <list>
1 Luke Skywalker 172 77 blond fair blue 19.0 male masculine Tatooine Human <chr [5]> <chr [2]> <chr [2]>
2 C-3PO 167 75 <NA> gold yellow 112.0 none masculine Tatooine Droid <chr [6]> <chr [0]> <chr [0]>
3 R2-D2 96 32 <NA> white, blue red 33.0 none masculine Naboo Droid <chr [7]> <chr [0]> <chr [0]>
4 Darth Vader 202 136 none white yellow 41.9 male masculine Tatooine Human <chr [4]> <chr [0]> <chr [1]>
--
84 Poe Dameron NA NA brown light brown NA male masculine <NA> Human <chr [1]> <chr [0]> <chr [1]>
85 BB8 NA NA none none black NA none masculine <NA> Droid <chr [1]> <chr [0]> <chr [0]>
86 Captain Phasma NA NA unknown unknown unknown NA <NA> <NA> <NA> <NA> <chr [1]> <chr [0]> <chr [0]>
87 Padmé Amidala 165 45 brown light brown 46.0 female feminine Naboo Human <chr [3]> <chr [0]> <chr [3]>
欠損値の補完 tidyr::replace_na()
欠損値 NA を任意の値で置き換える。
df = tibble(x = c(1, 2, NA), y = c("a", NA, "b"))
df %>% replace_na(list(x = 0, y = "unknown"))
x y
<dbl> <chr>
1 1 a
2 2 unknown
3 0 b
🔰 starwars で髪や目の色が不明の部分を"UNKNOWN"に置換しよう
name height mass hair_color skin_color eye_color birth_year sex gender homeworld species films vehicles starships
<chr> <int> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr> <chr> <chr> <list> <list> <list>
1 Luke Skywalker 172 77 blond fair blue 19.0 male masculine Tatooine Human <chr [5]> <chr [2]> <chr [2]>
2 C-3PO 167 75 <NA> gold yellow 112.0 none masculine Tatooine Droid <chr [6]> <chr [0]> <chr [0]>
3 R2-D2 96 32 <NA> white, blue red 33.0 none masculine Naboo Droid <chr [7]> <chr [0]> <chr [0]>
4 Darth Vader 202 136 none white yellow 41.9 male masculine Tatooine Human <chr [4]> <chr [0]> <chr [1]>
--
84 Poe Dameron NA NA brown light brown NA male masculine <NA> Human <chr [1]> <chr [0]> <chr [1]>
85 BB8 NA NA none none black NA none masculine <NA> Droid <chr [1]> <chr [0]> <chr [0]>
86 Captain Phasma NA NA unknown unknown unknown NA <NA> <NA> <NA> <NA> <chr [1]> <chr [0]> <chr [0]>
87 Padmé Amidala 165 45 brown light brown 46.0 female feminine Naboo Human <chr [3]> <chr [0]> <chr [3]>
欠損値とみなす dplyr::na_if()
特定の値を NA に置き換える:
df %>%
mutate(x = na_if(x, 1), y = na_if(y, "a"))
x y
<dbl> <chr>
1 NA <NA>
2 2 <NA>
3 NA b
🔰 starwars の性別"none"を欠損値にしよう
name height mass hair_color skin_color eye_color birth_year sex gender homeworld species films vehicles starships
<chr> <int> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr> <chr> <chr> <list> <list> <list>
1 Luke Skywalker 172 77 blond fair blue 19.0 male masculine Tatooine Human <chr [5]> <chr [2]> <chr [2]>
2 C-3PO 167 75 <NA> gold yellow 112.0 none masculine Tatooine Droid <chr [6]> <chr [0]> <chr [0]>
3 R2-D2 96 32 <NA> white, blue red 33.0 none masculine Naboo Droid <chr [7]> <chr [0]> <chr [0]>
4 Darth Vader 202 136 none white yellow 41.9 male masculine Tatooine Human <chr [4]> <chr [0]> <chr [1]>
--
84 Poe Dameron NA NA brown light brown NA male masculine <NA> Human <chr [1]> <chr [0]> <chr [1]>
85 BB8 NA NA none none black NA none masculine <NA> Droid <chr [1]> <chr [0]> <chr [0]>
86 Captain Phasma NA NA unknown unknown unknown NA <NA> <NA> <NA> <NA> <chr [1]> <chr [0]> <chr [0]>
87 Padmé Amidala 165 45 brown light brown 46.0 female feminine Naboo Human <chr [3]> <chr [0]> <chr [3]>
欠損値の補完 dplyr::coalesce()
先に指定した列が NA なら次の列の値を採用:
y = c(1, 2, NA, NA, 5)
z = c(NA, NA, 3, 4, 5)
coalesce(y, z)
[1] 1 2 3 4 5
異なる型を混ぜると怒られる:
df = tibble(x = c(1, 2, NA), y = c("a", NA, "b"))
df %>% mutate(z = coalesce(x, y))
Error in `mutate_cols()`:
! Problem with `mutate()` column `z`.
ℹ `z = coalesce(x, y)`.
✖ Can't combine `..1` <double> and `..2` <character>.
Caused by error in `stop_vctrs()`:
! Can't combine `..1` <double> and `..2` <character>.
🔰 starwars で髪色の欠損値を肌色で補おう
条件に応じて値を選択 dplyr::if_else()
普通の if, else とは違ってvector演算なのが特徴:
condition = c(TRUE, TRUE, FALSE)
x = c(1, 2, 3)
y = c(100, 200, 300)
if_else(condition, x, y)
[1] 1 2 300
🔰 starwars で種族がドロイドの行だけ身長を100倍してみよう
name height mass hair_color skin_color eye_color birth_year sex gender homeworld species films vehicles starships
<chr> <int> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr> <chr> <chr> <list> <list> <list>
1 Luke Skywalker 172 77 blond fair blue 19.0 male masculine Tatooine Human <chr [5]> <chr [2]> <chr [2]>
2 C-3PO 167 75 <NA> gold yellow 112.0 none masculine Tatooine Droid <chr [6]> <chr [0]> <chr [0]>
3 R2-D2 96 32 <NA> white, blue red 33.0 none masculine Naboo Droid <chr [7]> <chr [0]> <chr [0]>
4 Darth Vader 202 136 none white yellow 41.9 male masculine Tatooine Human <chr [4]> <chr [0]> <chr [1]>
--
84 Poe Dameron NA NA brown light brown NA male masculine <NA> Human <chr [1]> <chr [0]> <chr [1]>
85 BB8 NA NA none none black NA none masculine <NA> Droid <chr [1]> <chr [0]> <chr [0]>
86 Captain Phasma NA NA unknown unknown unknown NA <NA> <NA> <NA> <NA> <chr [1]> <chr [0]> <chr [0]>
87 Padmé Amidala 165 45 brown light brown 46.0 female feminine Naboo Human <chr [3]> <chr [0]> <chr [3]>
文字列: character型 (string)
ダブルクォートで囲む。シングルクォートも使える。
x = "This is a string"
y = 'If I want to include a "quote" inside a string, I use single quotes'
閉じそびれると変な状態になるので、落ち着いて esc or ctrlc
> "This is a string without a closing quote
+
+
+ HELP I'M STUCK
R備え付けの文字列機能は使いにくい
-
何をやる関数なのか名前から分かりにくい
grep,grepl,regexpr,gregexpr,regexec
sub,gsub,substr,substring -
対象文字列はいくつめに渡す?関数ごとに違う。e.g.,
grep(pattern, x, ...) sub(pattern, replacement, x, ...) substr(x, start, stop) -
欠損値
NAに対する挙動が微妙
stringr — 文字列処理パッケージ

stringr — 文字列処理パッケージ

文字列の基本操作
fruit4 = head(fruit, 4L) %>% print()
[1] "apple" "apricot" "avocado" "banana"
str_length(fruit4) # 長さ
[1] 5 7 7 6
str_sub(fruit4, 2, 4) # 部分抽出
[1] "ppl" "pri" "voc" "ana"
str_c(1:4, " ", fruit4, "!") # 結合
[1] "1 apple!" "2 apricot!" "3 avocado!" "4 banana!"
🔰 fruit や words の一部を抜き出して上記の関数を試してみよう
パターンマッチング
単純な一致だけじゃなく、いろんな条件でマッチングできる:
# aで始まる
str_subset(fruit, "^a")
[1] "apple" "apricot" "avocado"
# rで終わる
str_subset(fruit, "r$")
[1] "bell pepper" "chili pepper" "cucumber" "pear"
# 英数字3-4文字
str_subset(fruit, "^\\w{3,4}$")
[1] "date" "fig" "lime" "nut" "pear" "plum"
この ^ とか $ って何者?
正規表現: 柔軟な検索・置換を可能にするツール
| メタ文字 | 意味 | 演算子 | 意味 | |
|---|---|---|---|---|
\d |
数字 (逆は \D) |
? |
0回か1回 | |
\s |
空白 (逆は \S) |
* |
0回以上繰り返し | |
\w |
英数字 (逆は \W) |
+ |
1回以上繰り返し | |
. |
何でも1文字 | {n,m} |
n回以上m回以下 | |
^ |
行頭 | XXX(?=YYY) |
YYYに先立つXXX | |
$ |
行末 | (?<=YYY)XXX |
YYYに続くXXX |
https://unicode-org.github.io/icu/userguide/strings/regexp.html#regular-expression-metacharacters
Rの"普通の文字列"ではバックスラッシュを重ねる必要がある: "^\\d".
正規表現: チートシート

正規表現: 練習問題
🔰 str_subset(), fruit, words でパターンマッチを身に着けよう
- “o” で始まるもの
- “berry” で終わるもの
- “c” で始まり “r” で終わるもの
- 空白を含むもの、含まないもの
- 数字を含むもの、含まないもの
- そのほか自分で適当に考えてみる
検出 str_detect()
マッチするかどうか TRUE/FALSE を返す。
fruit4 = head(fruit, 4L)
str_detect(fruit4, "^a")
[1] TRUE TRUE TRUE FALSE
🔰 starwars から name 列に空白を含まない行を抽出しよう
name height mass hair_color skin_color eye_color birth_year sex gender homeworld species films vehicles starships
<chr> <int> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr> <chr> <chr> <list> <list> <list>
1 Luke Skywalker 172 77 blond fair blue 19.0 male masculine Tatooine Human <chr [5]> <chr [2]> <chr [2]>
2 C-3PO 167 75 <NA> gold yellow 112.0 none masculine Tatooine Droid <chr [6]> <chr [0]> <chr [0]>
3 R2-D2 96 32 <NA> white, blue red 33.0 none masculine Naboo Droid <chr [7]> <chr [0]> <chr [0]>
4 Darth Vader 202 136 none white yellow 41.9 male masculine Tatooine Human <chr [4]> <chr [0]> <chr [1]>
--
84 Poe Dameron NA NA brown light brown NA male masculine <NA> Human <chr [1]> <chr [0]> <chr [1]>
85 BB8 NA NA none none black NA none masculine <NA> Droid <chr [1]> <chr [0]> <chr [0]>
86 Captain Phasma NA NA unknown unknown unknown NA <NA> <NA> <NA> <NA> <chr [1]> <chr [0]> <chr [0]>
87 Padmé Amidala 165 45 brown light brown 46.0 female feminine Naboo Human <chr [3]> <chr [0]> <chr [3]>
抽出 str_extract()
マッチした部分文字列を取り出す。しなかった要素には NA。
fruit4 = head(fruit, 4L)
str_extract(fruit4, "^a..")
[1] "app" "apr" "avo" NA
🔰 diamonds の clarity 列を数字なしにしてみよう
carat cut color clarity depth table price x y z
<dbl> <ord> <ord> <ord> <dbl> <dbl> <int> <dbl> <dbl> <dbl>
1 0.23 Ideal E SI2 61.5 55 326 3.95 3.98 2.43
2 0.21 Premium E SI1 59.8 61 326 3.89 3.84 2.31
3 0.23 Good E VS1 56.9 65 327 4.05 4.07 2.31
4 0.29 Premium I VS2 62.4 58 334 4.20 4.23 2.63
--
53937 0.72 Good D SI1 63.1 55 2757 5.69 5.75 3.61
53938 0.70 Very Good D SI1 62.8 60 2757 5.66 5.68 3.56
53939 0.86 Premium H SI2 61.0 58 2757 6.15 6.12 3.74
53940 0.75 Ideal D SI2 62.2 55 2757 5.83 5.87 3.64
置換 str_replace(), str_replace_all()
カッコ () で囲んだマッチングは後で参照できる:
fruit4 = head(fruit, 4L)
str_replace(fruit4, "..$", "!!")
[1] "app!!" "apric!!" "avoca!!" "bana!!"
str_replace(fruit4, "(..)$", "_\\1_")
[1] "app_le_" "apric_ot_" "avoca_do_" "bana_na_"
🔰 starwars の name 列の数字を全部ゼロにしてみよう
name height mass hair_color skin_color eye_color birth_year sex gender homeworld species films vehicles starships
<chr> <int> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr> <chr> <chr> <list> <list> <list>
1 Luke Skywalker 172 77 blond fair blue 19 male masculine Tatooine Human <chr [5]> <chr [2]> <chr [2]>
2 C-3PO 167 75 <NA> gold yellow 112 none masculine Tatooine Droid <chr [6]> <chr [0]> <chr [0]>
3 R2-D2 96 32 <NA> white, blue red 33 none masculine Naboo Droid <chr [7]> <chr [0]> <chr [0]>
--
85 BB8 NA NA none none black NA none masculine <NA> Droid <chr [1]> <chr [0]> <chr [0]>
86 Captain Phasma NA NA unknown unknown unknown NA <NA> <NA> <NA> <NA> <chr [1]> <chr [0]> <chr [0]>
87 Padmé Amidala 165 45 brown light brown 46 female feminine Naboo Human <chr [3]> <chr [0]> <chr [3]>
dplyr, tidyr の列選択などでも活躍
matches() があれば starts_with()/ends_with() は不要:
diamonds %>% select(matches("^c")) # starts_with("c")
starwars %>% select(matches("s$")) # ends_with("s")
world_bank_pop %>%
pivot_longer(matches("^\\d+$"), names_to = "year")
See selection helpers for more details.
形式を変える・整える
fruit4 = head(fruit, 4L)
str_to_upper(fruit4) # 大文字に
[1] "APPLE" "APRICOT" "AVOCADO" "BANANA"
str_pad(fruit4, 8, "left", "_") # 幅を埋めて指定幅に
[1] "___apple" "_apricot" "_avocado" "__banana"
stringi パッケージはさらに多機能
stringi::stri_trans_nfkc(c("カタカナ", "42")) # 半角カナ・全角数字に対処
[1] "カタカナ" "42"
🔰 starwars の name 列を全部小文字にしてみよう
文字列から別の型に

これはstringrではなくreadrの担当:
parse_number(c("p = 0.02 *", "N_A = 6e23"))
[1] 2e-02 6e+23
parse_double(c("0.02", "6e+23"))
[1] 2e-02 6e+23
parse_logical(c("1", "true", "0", "false"))
[1] TRUE TRUE FALSE FALSE
parse_date("2020-06-03")
[1] "2020-06-03"
6e+23 は $6 \times 10 ^ {23}$ のプログラミング的表現。
$6e^{23}$ ではない。
因子型 factor
カテゴリカル変数(質的変数)を扱うための型。文字列っぽいけど実体は整数。
month_levels = c( # 取りうる値
"Jan", "Feb", "Mar", "Apr", "May", "Jun",
"Jul", "Aug", "Sep", "Oct", "Nov", "Dec"
)
x1 = c("Dec", "Apr", "Jan", "Mar") # ただの文字列vector
y1 = factor(x1, levels = month_levels) # 因子型に変換
print(y1)
[1] Dec Apr Jan Mar
Levels: Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec
as.integer(y1) # 整数型に変換可能
[1] 12 4 1 3
🔰 iris に含まれる因子型を確認しよう: str(iris)
因子型 factor: 文字列との違い1
取りうる値 (levels) が既知。
typoなどによりlevels外になると NA 扱い。
x2 = c("Dec", "Apr", "Jam", "Mar")
factor(x2, levels = month_levels)
[1] Dec Apr <NA> Mar
Levels: Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec
元の文字列vectorに全てのlevelsが含まれてるなら簡単に変換可能:
as.factor(starwars[["gender"]])
[1] masculine masculine masculine masculine feminine masculine feminine masculine masculine masculine masculine masculine masculine masculine masculine masculine masculine masculine masculine masculine masculine masculine masculine masculine masculine masculine feminine masculine masculine masculine masculine masculine masculine masculine masculine masculine <NA> masculine masculine <NA> feminine masculine masculine feminine masculine masculine masculine masculine masculine masculine masculine feminine masculine masculine masculine masculine masculine feminine masculine masculine feminine feminine feminine masculine masculine masculine feminine masculine masculine feminine feminine masculine feminine masculine masculine feminine masculine masculine masculine <NA> masculine masculine feminine masculine masculine <NA> feminine
Levels: feminine masculine
因子型 factor: 文字列との違い2
アルファベット順じゃない順序がある:
x1 = c("Dec", "Apr", "Jan", "Mar")
sort(x1) # 文字列としてソートするとアルファベット順
[1] "Apr" "Dec" "Jan" "Mar"
y1 = factor(x1, levels = month_levels)
sort(y1) # 因子としてソートするとlevels順
[1] Jan Mar Apr Dec
Levels: Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec
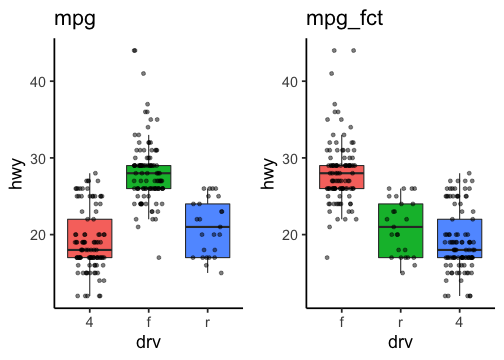
因子型 factor: 順序の情報は作図で生きる
文字列だと勝手にアルファベット順。因子型なら任意指定可能:
mpg_fct = mpg %>%
mutate(drv = factor(drv, levels = c("f", "r", "4")))
順序つき因子型 ordered
大小の比較ができる。
x1 = c("Dec", "Apr", "Jan", "Mar")
y3 = factor(x1, levels = month_levels, ordered = TRUE)
class(y3)
[1] "ordered" "factor"
print(y3)
[1] Dec Apr Jan Mar
Levels: Jan < Feb < Mar < Apr < May < Jun < Jul < Aug < Sep < Oct < Nov < Dec
y3 < "Sep"
[1] FALSE TRUE TRUE TRUE
🔰 diamonds に含まれるordered型を確認しよう: str(diamonds)
🔰 cut がPremium以上の行だけ抜き出す、とか。
tidyverse の因子型担当は forcats

fct_relevel(): 手動で順序設定fct_reorder(): 別の変数に応じて順序を並べ替えfct_infreq(): 頻度に応じて順序を並べ替えfct_lump(): 少なすぎるカテゴリを"その他"としてまとめる
diamonds_fct = diamonds %>%
mutate(color = fct_infreq(color))
mpg_fct = mpg %>%
mutate(fl = fct_lump(fl, n = 2))
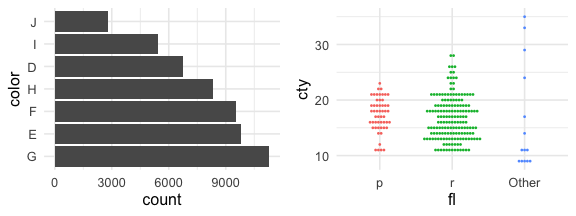
factorで順序を変えて作図する練習
🔰 mpg で次のような図を描いてみよう
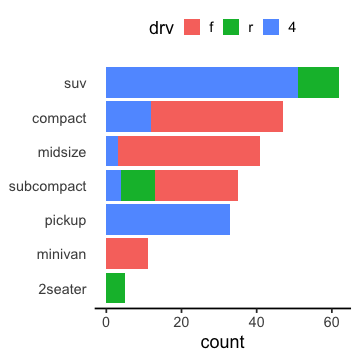
指示変数(ダミー変数)に変換
イチゼロの値を持たせて横広に変形するのと等価。
iris %>% rowid_to_column() %>%
mutate(value = 1L) %>%
pivot_wider(names_from = Species,
values_from = value, values_fill = 0L)
rowid Sepal.Length Sepal.Width Petal.Length Petal.Width setosa versicolor virginica
<int> <dbl> <dbl> <dbl> <dbl> <int> <int> <int>
1 1 5.1 3.5 1.4 0.2 1 0 0
2 2 4.9 3.0 1.4 0.2 1 0 0
3 3 4.7 3.2 1.3 0.2 1 0 0
4 4 4.6 3.1 1.5 0.2 1 0 0
--
147 147 6.3 2.5 5.0 1.9 0 0 1
148 148 6.5 3.0 5.2 2.0 0 0 1
149 149 6.2 3.4 5.4 2.3 0 0 1
150 150 5.9 3.0 5.1 1.8 0 0 1
🔰 これを元の iris に戻してみよう
日時型: POSIXct, POSIXlt
- POSIXct: エポックからの経過秒数。比較や差分などを取りやすい。
- POSIXlt: list(秒, 分, 時, 日, 月, 年, …)。単位ごとに抜き出しやすい。
now = "2021-09-15 11:00:00"
ct = as.POSIXct(now)
unclass(ct)
[1] 1631671200
attr(,"tzone")
[1] ""
lt = as.POSIXlt(now)
unclass(lt) %>% as_tibble()
sec min hour mday mon year wday yday isdst zone gmtoff
<dbl> <int> <int> <int> <int> <int> <int> <int> <int> <chr> <int>
1 0 0 11 15 8 121 3 257 0 JST NA
素のRでも扱えるけど lubridate パッケージを使うともっと楽に。
lubridate — 日時型処理パッケージ

日時型への変換:
ymd(c("20201017", "2020-10-17", "20/10/17"))
[1] "2020-10-17" "2020-10-17" "2020-10-17"
日時型から単位ごとに値を取得:
today = ymd(20201017)
month(today)
[1] 10
wday(today, label = TRUE)
[1] Sat
Levels: Sun < Mon < Tue < Wed < Thu < Fri < Sat
🔰 公式ドキュメントなどを見ていろいろな変換・抽出を試してみよう
データ内容を対象とする処理 | まとめ
- 正規化・欠損値処理は目的に応じて検討
- vectorには型がある: 文字列、数値、因子、日時、etc.
- 文字列を扱うには stringr
- 正規表現は一度習得すれば超強力
- 因子を扱うには forcats
- 知っておくとたまに便利。苦手なら全部文字列にしてもいい。
- 日時を扱うには lubridate
各パッケージのチートシート.pdfを手元に持っておくと便利。
前処理に必要な道具はだいたい揃った
- データ構造を対象とする処理 — 第3, 4回
- 使いたい部分だけ抽出 —
select(),filter() - グループごとに特徴を要約 —
group_by(),summarize() - 何かの順に並べ替え —
arrange() - 異なるテーブルの結合 —
*_join() - 変形: 縦長 ↔ 横広 —
pivot_longer(),pivot_wider()
- 使いたい部分だけ抽出 —
- データ内容を対象とする処理 — 👈 第5回 本日の話題
- 数値の変換: 対数、正規化
- 外れ値・欠損値への対処
- 型変換: 連続変数、カテゴリカル変数、指示変数、因子、日時
- 文字列処理: 正規表現によるパターンマッチ
統計解析の一歩手前までなら行ける
- コンピュータ環境の整備
- データの取得、読み込み
- 探索的データ解析
- 前処理、加工 (地味。意外と重い) 👈 本実習の主題
- 可視化、仮説生成 (派手!だいじ!)
- 統計解析、仮説検証 (みんな勉強したがる)
- 報告、発表
🔰 3日目の課題1: 好きなデータをいじくり倒してみよう
- 自分がこれから解析したいデータ (もし手元にあれば)
- 何か適当なパブリックデータ。例えば:
- e-Stat: 政府統計の総合窓口
- data.go.jp データカタログサイト: 中央省庁
- BODIKオープンデータカタログサイト: 地方自治体
- 気象庁
- DATA.GOV: U.S. Government’s open data
- (苦肉の策) Rやパッケージに付属のデータ
diamonds,starwars,mpg, etc. Seedata()
- 発表・レポートの条件
- 最低1枚の図と、そこに至る前処理+可視化のコード。
- グラフから読み取れることを一言。
実演: 目黒区オープンデータ
町丁別・年齢別・男女別人口… の最新CSVをダウンロード、読み込み
infile = "131105_population_20211001.csv"
raw_meguro = readr::read_csv(infile)
print(raw_meguro)
都道府県コード又は市区町村コード 地域コード 都道府県名 市区町村名 調査年月日 地域名 総人口 男性 女性 0-4歳の男性 0-4歳の女性 5-9歳の男性 5-9歳の女性 10-14歳の男性 10-14歳の女性 15-19歳の男性 15-19歳の女性 20-24歳の男性 20-24歳の女性 25-29歳の男性 25-29歳の女性 30-34歳の男性 30-34歳の女性 35-39歳の男性 35-39歳の女性 40-44歳の男性 40-44歳の女性 45-49歳の男性 45-49歳の女性 50-54歳の男性 50-54歳の女性 55-59歳の男性 55-59歳の女性 60-64歳の男性 60-64歳の女性 65-69歳の男性 65-69歳の女性 70-74歳の男性 70-74歳の女性 75-79歳の男性 75-79歳の女性 80-84歳の男性 80-84歳の女性 85歳以上の男性 85歳以上の女性 不詳者の男性 不詳者の女性 世帯数 備考 KEY_CODE
<dbl> <dbl> <chr> <chr> <date> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <lgl> <dbl>
1 131105 111 東京都 目黒区 2021-10-01 駒場一丁目 4095 2108 1987 69 59 76 68 76 66 68 52 167 129 226 173 221 136 172 149 184 144 177 185 146 144 111 110 74 91 76 95 110 118 57 94 48 62 50 112 0 0 2487 NA 13110001001
2 131105 112 東京都 目黒区 2021-10-01 駒場二丁目 556 270 286 5 7 10 5 10 9 18 14 18 17 26 25 18 16 21 16 18 16 19 23 19 23 16 15 18 16 7 12 16 22 13 16 10 11 8 23 0 0 332 NA 13110001002
3 131105 113 東京都 目黒区 2021-10-01 駒場三丁目 872 429 443 10 17 15 17 18 18 18 14 25 23 36 26 28 23 32 33 27 27 41 45 39 43 31 28 24 21 18 20 22 31 19 23 10 14 16 20 0 0 479 NA 13110001003
4 131105 114 東京都 目黒区 2021-10-01 駒場四丁目 1258 581 677 13 14 26 27 38 21 37 30 34 42 36 29 37 47 30 34 48 61 55 63 47 66 37 58 32 29 27 32 32 48 23 26 13 18 16 32 0 0 666 NA 13110001004
--
85 131105 364 東京都 目黒区 2021-10-01 八雲四丁目 2089 969 1120 30 34 47 44 56 54 44 44 51 44 64 57 43 60 52 66 70 104 98 110 88 101 84 82 49 56 43 56 60 65 37 50 21 38 32 55 0 0 991 NA 13110026004
86 131105 365 東京都 目黒区 2021-10-01 八雲五丁目 2851 1370 1481 73 53 79 58 81 71 59 68 78 61 74 75 82 98 96 118 128 127 102 130 112 116 103 113 83 95 60 63 69 63 30 61 31 43 30 68 0 0 1343 NA 13110026005
87 131105 371 東京都 目黒区 2021-10-01 東が丘一丁目 4476 2092 2384 105 79 112 102 118 99 111 92 104 142 116 138 125 155 150 176 179 203 187 195 173 194 148 174 112 129 94 90 98 119 69 82 45 73 46 142 0 0 2215 NA 13110027001
88 131105 372 東京都 目黒区 2021-10-01 東が丘二丁目 3114 1360 1754 65 62 66 54 59 48 40 49 88 200 140 218 119 162 108 150 99 121 112 111 90 122 97 101 80 76 53 57 40 74 42 47 35 40 27 62 0 0 1796 NA 13110027002
実演: 目黒区オープンデータ
ggplotしたくなる形に変形。1行ずつ経過を確認しよう。
tidy_meguro = raw_meguro %>%
select("地域名", matches("の.+性$")) %>%
rename(place = 地域名) %>%
mutate(place = str_remove(place, "\\S丁目")) %>%
group_by(place) %>%
summarize(across(everything(), sum)) %>%
ungroup() %>%
pivot_longer(!place, names_to = "category", values_to = "count") %>%
separate(category, c("age", "sex"), sep = "の") %>%
mutate(age = as.integer(str_extract(age, "^\\d+"))) %>%
filter(!is.na(age)) %>%
print()
place age sex count
<chr> <int> <chr> <dbl>
1 三田 0 男性 92
2 三田 0 女性 84
3 三田 5 男性 98
4 三田 5 女性 93
--
969 鷹番 80 男性 113
970 鷹番 80 女性 182
971 鷹番 85 男性 126
972 鷹番 85 女性 276
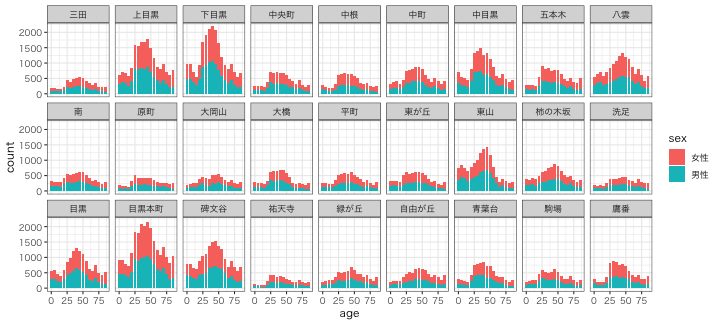
実演: 目黒区オープンデータ
作図してみる
ggplot(tidy_meguro) +
aes(age, count) +
geom_col(aes(fill = sex)) +
facet_wrap(vars(place), nrow = 3L) +
theme_bw(base_family = "HiraginoSans-W3") # 日本語は鬼門
実演: e-Stat 国勢調査2015 (宮城県)
文字コードが古い。列名が2行にまたがってる。数値の列に変な文字。
infile = "tblT000849C04.txt"
sjis = locale(encoding = "SJIS")
# readr::read_csv(infile, locale = sjis)
miyagi_L = readr::read_csv(infile, locale = sjis, col_select = seq(1, 7)) %>%
dplyr::slice(-1)
miyagi_R = readr::read_csv(infile, locale = sjis, col_select = -seq(1, 7), skip = 1L, na = c("-", "X"), name_repair = "minimal")
raw_miyagi = bind_cols(miyagi_L, miyagi_R) %>% print()
KEY_CODE HYOSYO CITYNAME NAME HTKSYORI HTKSAKI GASSAN 総数、年齢「不詳」含む 総数0〜4歳 総数5〜9歳 総数10〜14歳 総数15〜19歳 総数20〜24歳 総数25〜29歳 総数30〜34歳 総数35〜39歳 総数40〜44歳 総数45〜49歳 総数50〜54歳 総数55〜59歳 総数60〜64歳 総数65〜69歳 総数70〜74歳 総数15歳未満 総数15〜64歳 総数65歳以上 総数75歳以上 男の総数、年齢「不詳」含む 男0〜4歳 男5〜9歳 男10〜14歳 男15〜19歳 男20〜24歳 男25〜29歳 男30〜34歳 男35〜39歳 男40〜44歳 男45〜49歳 男50〜54歳 男55〜59歳 男60〜64歳 男65〜69歳 男70〜74歳 男15歳未満 男15〜64歳 男65歳以上 男75歳以上 女の総数、年齢「不詳」含む 女0〜4歳 女5〜9歳 女10〜14歳 女15〜19歳 女20〜24歳 女25〜29歳 女30〜34歳 女35〜39歳 女40〜44歳 女45〜49歳 女50〜54歳 女55〜59歳 女60〜64歳 女65〜69歳 女70〜74歳 女15歳未満 女15〜64歳 女65歳以上 女75歳以上
<chr> <dbl> <chr> <chr> <dbl> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 04101 1 仙台市青葉区 <NA> 0 <NA> <NA> 310183 11107 11396 11605 16730 25517 20314 19691 20935 23107 20324 18759 17648 18731 19288 14488 34108 201756 66000 32224 150535 5691 5819 5997 8641 13205 10180 9578 10244 11460 10204 9424 8525 8999 9058 6607 17507 100460 27716 12051 159648 5416 5577 5608 8089 12312 10134 10113 10691 11647 10120 9335 9123 9732 10230 7881 16601 101296 38284 20173
2 041010010 2 仙台市青葉区 青葉町 0 <NA> <NA> 697 22 20 21 26 50 87 58 43 41 58 30 34 49 38 30 63 476 145 77 319 11 9 9 12 23 43 32 18 14 29 14 13 20 17 14 29 218 62 31 378 11 11 12 14 27 44 26 25 27 29 16 21 29 21 16 34 258 83 46
3 041010020 2 仙台市青葉区 あけぼの町 0 <NA> <NA> 798 22 18 16 35 60 77 59 61 58 47 44 33 55 50 46 56 529 201 105 394 15 8 11 19 26 39 26 36 35 25 16 18 27 29 22 34 267 88 37 404 7 10 5 16 34 38 33 25 23 22 28 15 28 21 24 22 262 113 68
4 041010030 2 仙台市青葉区 旭ケ丘 0 <NA> <NA> 8958 245 260 258 347 824 939 771 662 731 597 505 451 414 407 322 763 6241 1780 1051 4239 139 131 139 174 335 439 357 316 361 308 251 236 198 197 142 409 2975 741 402 4719 106 129 119 173 489 500 414 346 370 289 254 215 216 210 180 354 3266 1039 649
--
5880 04606004015 3 本吉郡南三陸町 歌津字石浜 0 <NA> <NA> 242 5 9 7 7 8 6 11 11 15 17 26 18 26 21 18 21 145 76 37 122 3 5 3 4 5 2 6 5 8 12 12 8 12 15 6 11 74 37 16 120 2 4 4 3 3 4 5 6 7 5 14 10 14 6 12 10 71 39 21
5881 04606004016 3 本吉郡南三陸町 歌津字田の浦 0 <NA> <NA> 181 4 4 4 10 8 11 13 5 4 15 13 22 17 5 8 12 118 51 38 86 1 2 3 6 4 6 7 2 3 5 5 12 11 5 2 6 61 19 12 95 3 2 1 4 4 5 6 3 1 10 8 10 6 NA 6 6 57 32 26
5882 04606004017 3 本吉郡南三陸町 歌津字草木沢 0 <NA> <NA> 466 14 17 22 18 17 25 28 16 40 29 21 33 49 39 34 53 276 137 64 246 6 7 10 12 6 14 18 12 21 16 12 18 22 26 17 23 151 72 29 220 8 10 12 6 11 11 10 4 19 13 9 15 27 13 17 30 125 65 35
5883 04606004018 3 本吉郡南三陸町 歌津字伊里前 0 <NA> <NA> NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA
実演: e-Stat 国勢調査2015 (宮城県)
まだ罠がたくさん: 列名の頭にスペース。全角数字。変な区分。
tidy_miyagi = raw_miyagi %>%
dplyr::filter(HYOSYO == 1) %>%
dplyr::select(CITYNAME, matches("[男女].+[歳上]$")) %>%
tidyr::pivot_longer(!CITYNAME, names_to = "category", values_to = "count") %>%
dplyr::mutate(category = str_trim(category)) %>%
tidyr::separate(category, c("sex", "age"), 1) %>%
dplyr::mutate(age = stringi::stri_trans_nfkc(age)) %>%
tidyr::separate(age, c("lower", "upper"), "〜", fill = "right") %>%
dplyr::mutate(lower = parse_number(lower), upper = parse_number(upper)) %>%
dplyr::filter((upper - lower) < 5 | lower == 75) %>%
dplyr::rename(age = lower) %>%
print()
CITYNAME sex age upper count
<chr> <chr> <dbl> <dbl> <dbl>
1 仙台市青葉区 男 0 4 5691
2 仙台市青葉区 男 5 9 5819
3 仙台市青葉区 男 10 14 5997
4 仙台市青葉区 男 15 19 8641
--
1245 本吉郡南三陸町 女 60 64 519
1246 本吉郡南三陸町 女 65 69 442
1247 本吉郡南三陸町 女 70 74 381
1248 本吉郡南三陸町 女 75 NA 1487
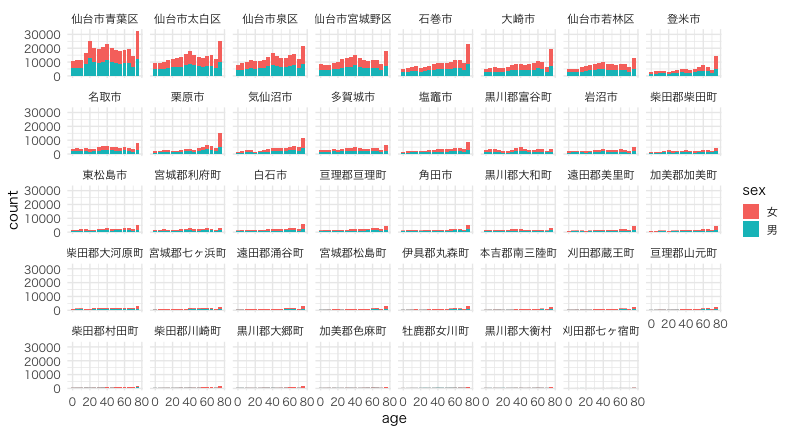
実演: e-Stat 国勢調査2015 (宮城県)
ggplot(tidy_miyagi) +
aes(age, count) +
geom_col(aes(fill = sex)) +
facet_wrap(vars(CITYNAME), ncol = 8L) +
theme_minimal(base_family = "HiraginoSans-W3", base_size = 14)
Reference
- R for Data Science — Hadley Wickham and Garrett Grolemund
- https://r4ds.had.co.nz/, Paperback, 日本語版書籍
前処理大全 — 本橋智光
RユーザのためのRStudio[実践]入門 (宇宙船本) — 松村ら
- Official documents:
- tidyverse, dplyr, tidyr, stringr, forcats, lubridate
- Older versions
- 「Rにやらせて楽しよう — データの可視化と下ごしらえ」 岩嵜航 2018
- 「Rを用いたデータ解析の基礎と応用」石川由希 2019 名古屋大学
- 「Rによるデータ前処理実習」 岩嵜航 2020 東京医科歯科大
- 「Rを用いたデータ解析の基礎と応用」 石川由希 2021 名古屋大学