Rによるデータ前処理実習2024
(Graduate School of Life Sciences, Tohoku University)
- 入門1: 前処理とは。Rを使うメリット。Rの基本。
- 入門2: データ可視化の重要性と方法。
- データ構造の処理1: 抽出、集約など。
- データ構造の処理2: 結合、変形など。
- データ内容の処理: 数値、文字列、日時など。
- 実践: 現実の問題に対処してみる。
https://heavywatal.github.io/slides/tmd2024/
作業再開
- このページを手元のウェブブラウザで開く。
- 先日作った
r-training-2024.Rprojをダブルクリック。
正しい working directory でRStudioが起動される。 - 今日のぶんのスクリプトを新規作成し、好きな名前で保存。
- tidyverse読み込みやパレット設定などのおまじないをまず実行。
前回までのまとめ
✅ データ解析全体の流れ。可視化だいじ
✅ Rを使えば無料で楽に再現可能な解析が可能
✅ Rの基礎
- 調べ方さえわかれば、全部覚えなくても大丈夫
- エラーは日常茶飯事。落ち着いて読み取ろう
- まずRスクリプトに書いてから、コンソールで実行
- 便利なパッケージを使おう
✅ 一貫性のある文法で合理的に描けるggplot2
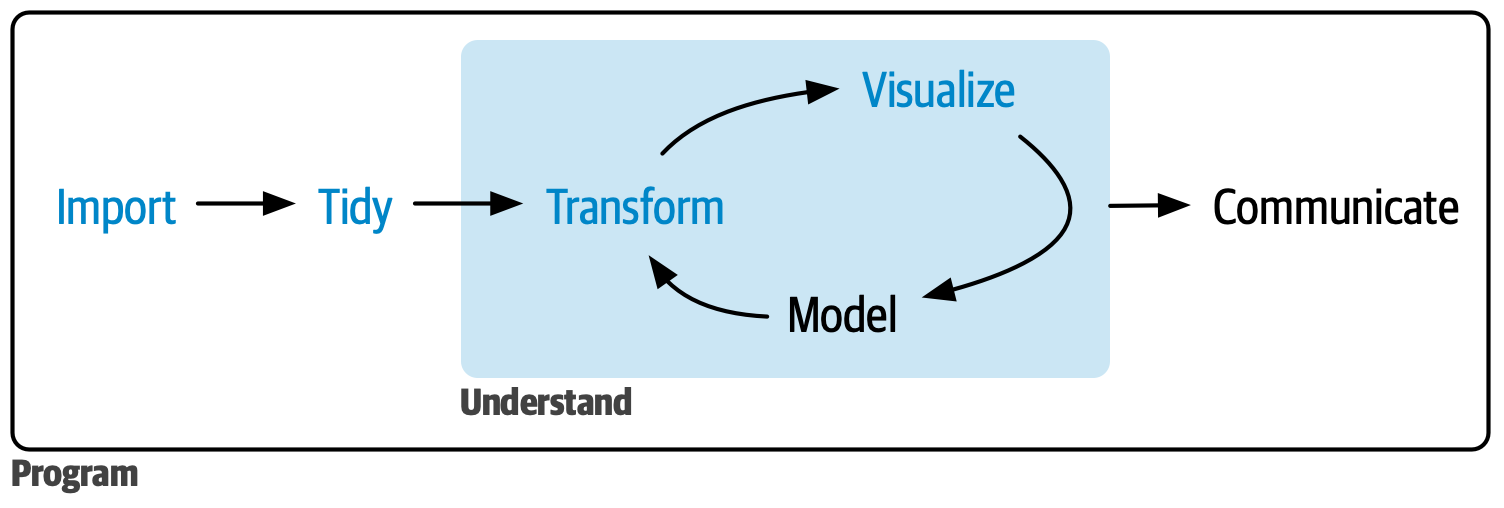
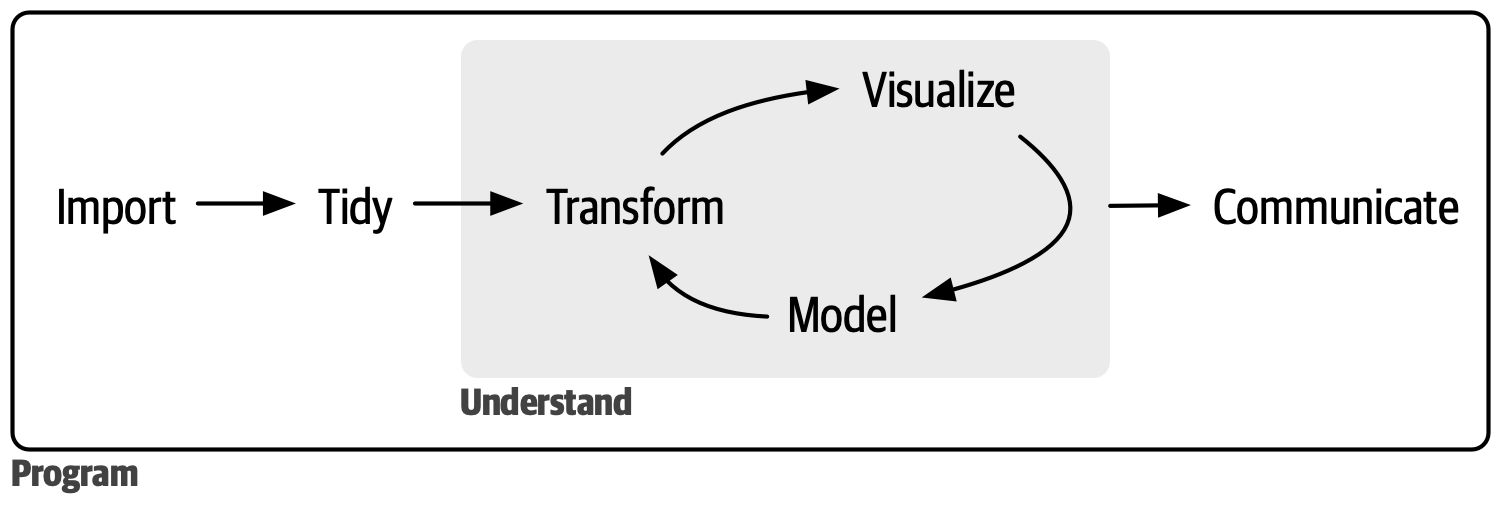
データ解析のおおまかな流れ
- コンピュータ環境の整備 ✅
- データの取得、読み込み ⬜
- 探索的データ解析
- 前処理、加工 (地味。意外と重い) 👈 今回の主題
- 可視化、仮説生成 (派手!だいじ!) ✅ 完全に理解した
- 統計解析、仮説検証 (みんな勉強したがる)
- 報告、発表
可視化だいじ。わかった。
情報の整理 → 正しい解析・新しい発見・仮説生成
でもデータ分析に費やす労力の8割は前処理らしいよ。。。
機械処理しやすい形 vs 人が読み書きしやすい形
- 作図や解析に使えるデータ形式はほぼ決まってる
ggplot(data, ...),glm(..., data, ...), …- 出発点となるデータはさまざま
- 実験ノート、フィールドノート、データベース、…
Happy families are all alike;
every unhappy family is unhappy in its own way
tidy datasets are all alike,
but every messy dataset is messy in its own way
整然データ tidy data vs 雑然データ messy data
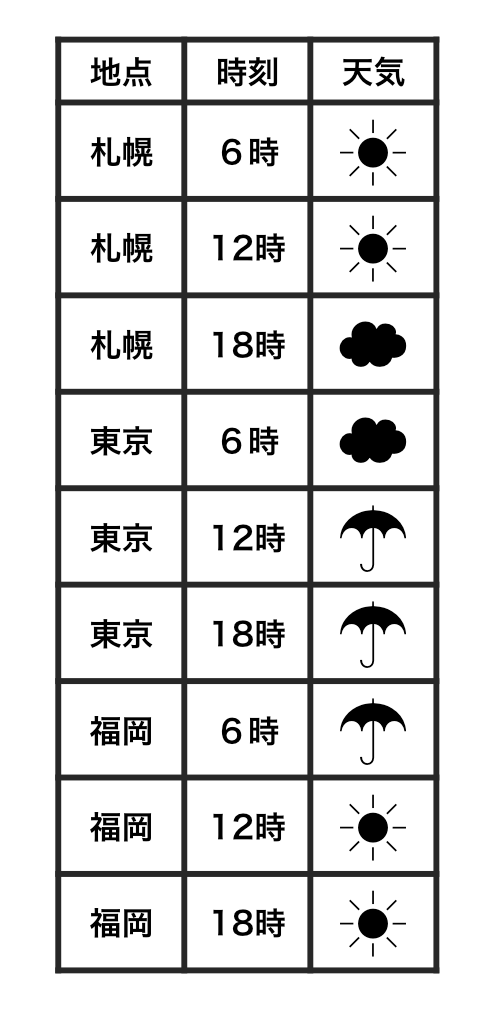
横1行は1つの観測
1セルは1つの値
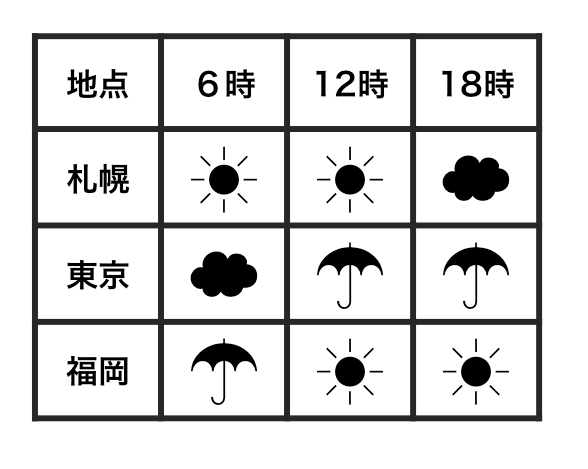
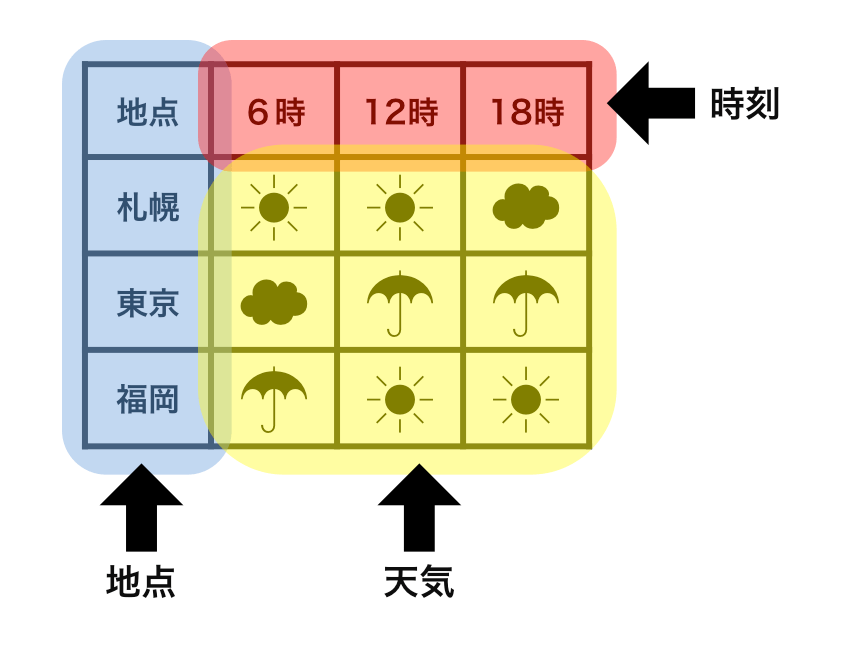
整然データ tidy data vs 雑然データ messy data
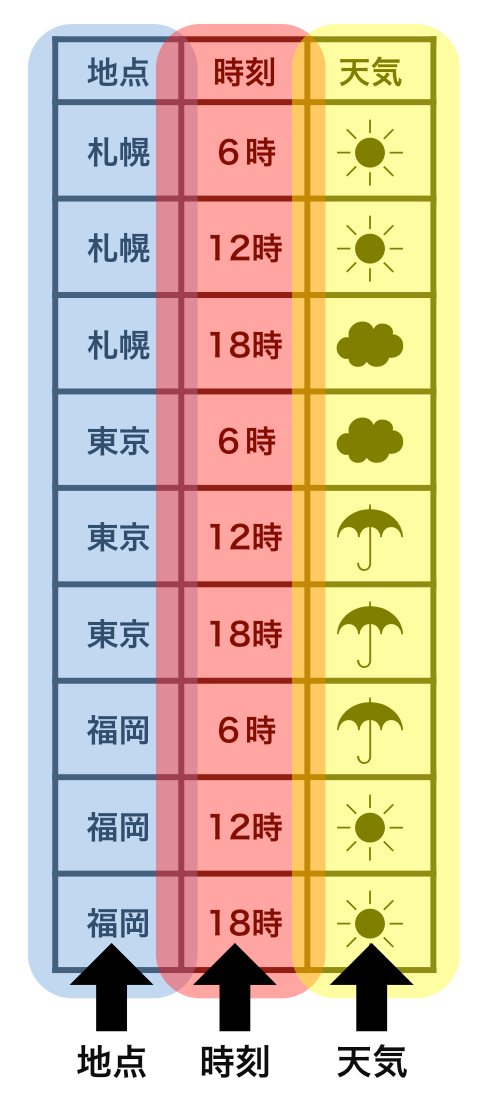
横1行は1つの観測
1セルは1つの値
整然データ tidy data vs 雑然データ messy data
横1行は1つの観測
1セルは1つの値
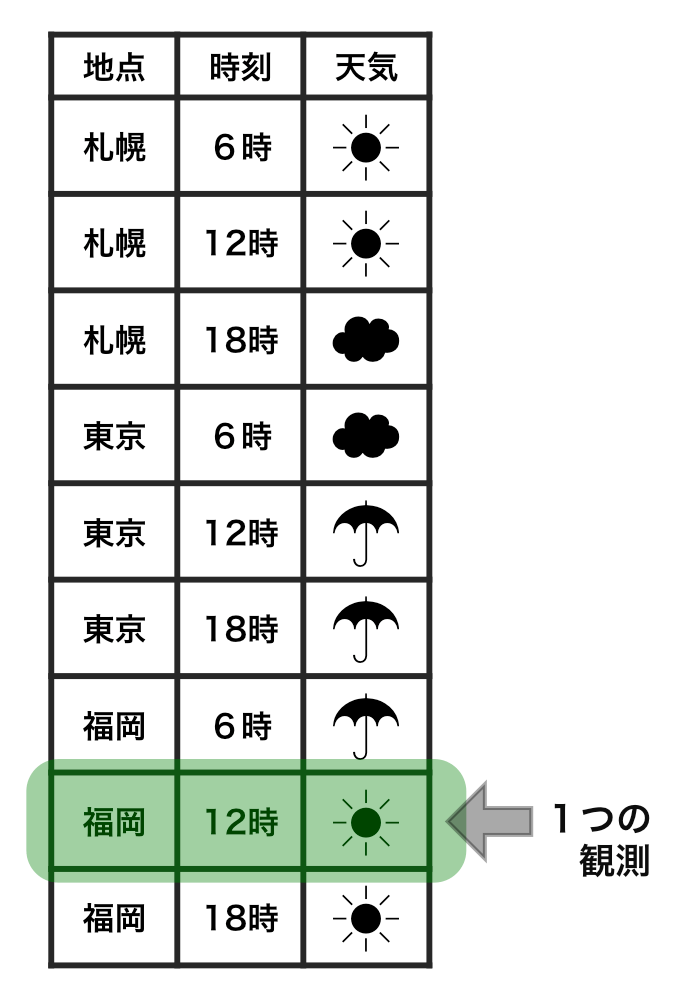
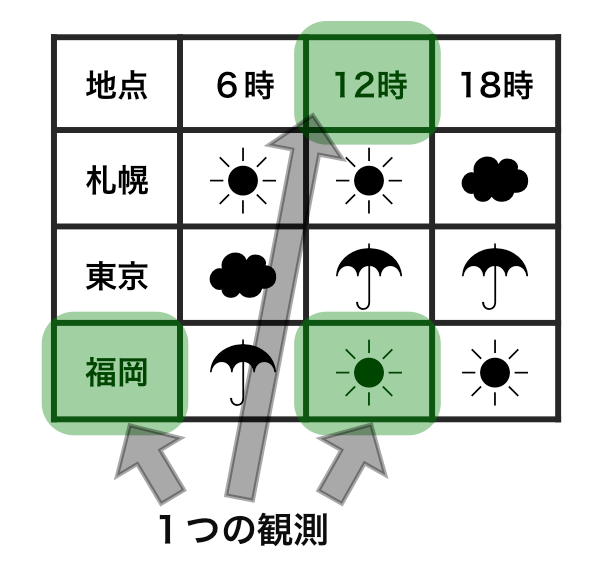
整然データ tidy data vs 雑然データ messy data
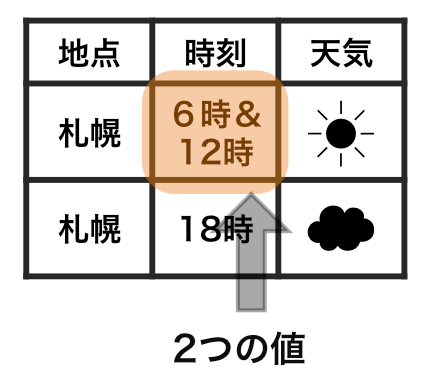
横1行は1つの観測
1セルは1つの値
整然データ tidy data ≈ ggplot したくなる形
- 縦1列は1つの変数
- 横1行は1つの観測
- 1セルは1つの値
https://r4ds.hadley.nz/data-tidy.html
print(ggplot2::diamonds)
carat cut color clarity depth table price x y z
1 0.23 Ideal E SI2 61.5 55 326 3.95 3.98 2.43
2 0.21 Premium E SI1 59.8 61 326 3.89 3.84 2.31
3 0.23 Good E VS1 56.9 65 327 4.05 4.07 2.31
4 0.29 Premium I VS2 62.4 58 334 4.20 4.23 2.63
--
53937 0.72 Good D SI1 63.1 55 2757 5.69 5.75 3.61
53938 0.70 Very Good D SI1 62.8 60 2757 5.66 5.68 3.56
53939 0.86 Premium H SI2 61.0 58 2757 6.15 6.12 3.74
53940 0.75 Ideal D SI2 62.2 55 2757 5.83 5.87 3.64
整然データ tidy data ≈ ggplot したくなる形
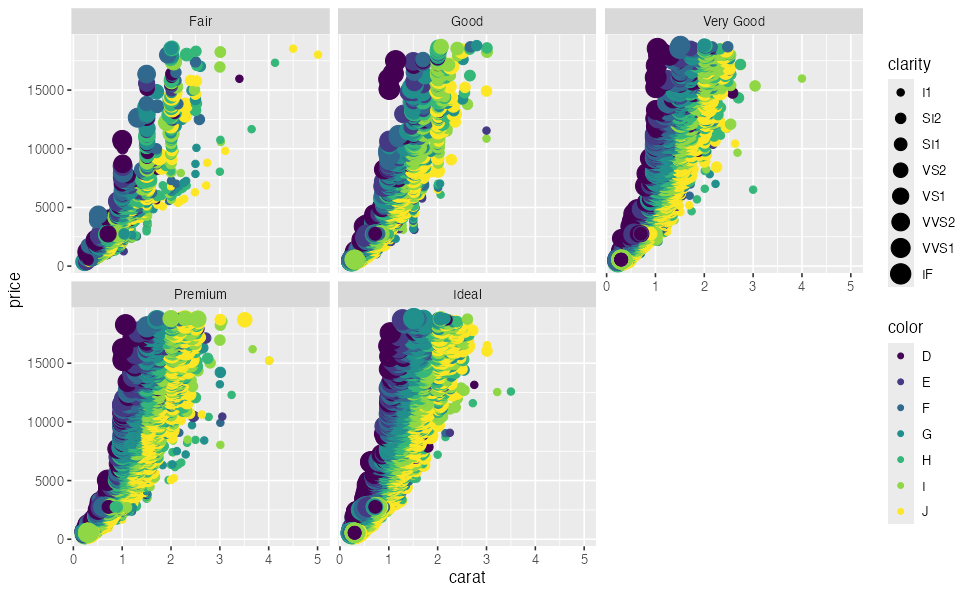
x軸、y軸、色分け、パネル分けなどを列の名前で指定して簡単作図:
ggplot(diamonds) + aes(x = carat, y = price) +
geom_point(mapping = aes(color = color, size = clarity)) +
facet_wrap(vars(cut))
目標: 生データを下ごしらえして食べやすい形に
print(VADeaths)
Rural Male Rural Female Urban Male Urban Female
50-54 11.7 8.7 15.4 8.4
55-59 18.1 11.7 24.3 13.6
60-64 26.9 20.3 37.0 19.3
65-69 41.0 30.9 54.6 35.1
70-74 66.0 54.3 71.1 50.0
↓ 下ごしらえ: 作図・解析で使いやすい整然データに
lbound ubound region sex death
1 50 54 Rural Male 11.7
2 50 54 Rural Female 8.7
3 50 54 Urban Male 15.4
4 50 54 Urban Female 8.4
--
17 70 74 Rural Male 66.0
18 70 74 Rural Female 54.3
19 70 74 Urban Male 71.1
20 70 74 Urban Female 50.0
前処理は大きく2つに分けられる
- データ構造を対象とする処理 👈 第3, 4回 本日の話題
- 使いたい部分だけ抽出
- グループごとに特徴を要約
- 何かの順に並べ替え
- 異なるテーブルの結合
- 変形: 縦長 ↔ 横広
- データ内容を対象とする処理 — 第5回 来週
- 数値の変換: 対数、正規化
- 外れ値・欠損値への対処
- 型変換: 連続変数、カテゴリカル変数、指示変数、因子、日時
- 文字列処理: 正規表現によるパターンマッチ
tidyverse: データ科学のためのパッケージ群
install.packages("tidyverse")
library(conflicted) # 安全のおまじない
library(tidyverse) # 一挙に読み込み
── Attaching core tidyverse packages ──── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.5.1 ✔ tibble 3.2.1
✔ lubridate 1.9.4 ✔ tidyr 1.3.1
✔ purrr 1.0.4
一貫したデザインでデータ解析の様々な工程をカバー
dplyr — data.frameの高速処理担当

シンプルな関数がたくさん。繋げて使う (piping)
- 抽出
- 列:
select(), - 行:
filter(),distinct(),slice() - 要約・集計
group_by(),summarize(),count()- 並べ替え
arrange(),relocate()- 列の追加・変更
mutate(),rename()- 結合
- 行方向:
bind_rows() - 列方向:
left_join(),inner_join(),full_join()
dplyrを使ってみる準備
パッケージを読み込んで、データを見てみる
# install.packages("tidyverse")
library(conflicted) # 安全のおまじない
library(tidyverse)
print(diamonds)
View(diamonds) # RStudio
carat cut color clarity depth table price x y z
1 0.23 Ideal E SI2 61.5 55 326 3.95 3.98 2.43
2 0.21 Premium E SI1 59.8 61 326 3.89 3.84 2.31
3 0.23 Good E VS1 56.9 65 327 4.05 4.07 2.31
4 0.29 Premium I VS2 62.4 58 334 4.20 4.23 2.63
--
53937 0.72 Good D SI1 63.1 55 2757 5.69 5.75 3.61
53938 0.70 Very Good D SI1 62.8 60 2757 5.66 5.68 3.56
53939 0.86 Premium H SI2 61.0 58 2757 6.15 6.12 3.74
53940 0.75 Ideal D SI2 62.2 55 2757 5.83 5.87 3.64
🔰 starwars データも眺めてみよう
dplyr の関数を使うときのお作法
名前空間を明示する演算子 :: を使う:
dplyr::filter(diamonds, carat > 3)
carat cut color clarity depth table price x y z
1 3.01 Premium I I1 62.7 58 8040 9.10 8.97 5.67
2 3.11 Fair J I1 65.9 57 9823 9.15 9.02 5.98
3 3.01 Premium F I1 62.2 56 9925 9.24 9.13 5.73
4 3.05 Premium E I1 60.9 58 10453 9.26 9.25 5.66
--
29 3.01 Good H SI2 57.6 64 18593 9.44 9.38 5.42
30 3.51 Premium J VS2 62.5 59 18701 9.66 9.63 6.03
31 3.01 Premium J SI2 60.7 59 18710 9.35 9.22 5.64
32 3.01 Premium J SI2 59.7 58 18710 9.41 9.32 5.59
同名の関数と衝突する場合(ここではR標準の stats::filter())、
「私が使いたいのは dplyrのほうの filter() です」と明示したい。
そうじゃなくても「この関数はあのパッケージ由来」が分かって便利。
dplyr はこういうふうに使いやすい
小さな関数を繋げて使う流れ作業:
result = diamonds |> # 生データから出発して
dplyr::select(carat, cut, price) |> # 列を抽出して
dplyr::filter(carat > 1) |> # 行を抽出して
dplyr::group_by(cut) |> # グループ化して
dplyr::summarize(mean(price)) |> # 平均を計算
print() # 表示してみる
cut mean(price)
1 Fair 7177.856
2 Good 7753.601
3 Very Good 8340.549
4 Premium 8487.249
5 Ideal 8674.227
この見慣れぬ記号 |> は何?
(select() など個々の関数は後で触れるとして)
Pipe operator (パイプ演算子) |>
パイプの左側の変数を、右側の関数の第一引数にねじ込む:
diamonds |> filter(carat > 1)
filter(diamonds, carat > 1) # これと同じ
# 前処理の流れ作業に便利:
diamonds |> filter(carat > 1) |> select(carat, price) |> ...
potatoes |> cut() |> fry() |> season("salt") |> eat()
🔰 パイプを使わない形に書き換え、出力を確認しよう:
seq(1, 6) |> sum()
[1] 21
letters |> toupper() |> head(3)
[1] "A" "B" "C"
↓解答例
↓
↓
sum(seq(1, 6))
[1] 21
head(toupper(letters), 3)
[1] "A" "B" "C"
パイプ演算子 |> を使わない方法
😐 一時変数をイチイチ作る:
tmp1 = dplyr::select(diamonds, carat, cut, price) # 列を抽出して
tmp2 = dplyr::filter(tmp1, carat > 1) # 行を抽出して
tmp3 = dplyr::group_by(tmp2, cut) # グループ化して
result = dplyr::summarize(tmp3, mean(price)) # 平均を計算
😐 同じ名前を使い回す:
result = dplyr::select(diamonds, carat, cut, price) # 列を抽出して
result = dplyr::filter(result, carat > 1) # 行を抽出して
result = dplyr::group_by(result, cut) # グループ化して
result = dplyr::summarize(result, mean(price)) # 平均を計算
どちらも悪くない。 何度も変数名を入力するのがやや冗長。
パイプ演算子 |> を使わない方法
😫 一時変数を使わずに:
result = dplyr::summarize( # 平均を計算
dplyr::group_by( # グループ化して
dplyr::filter( # 行を抽出して
dplyr::select(diamonds, carat, cut, price), # 列を抽出して
carat > 1), # 行を抽出して
cut), # グループ化して
mean(price)) # 平均を計算
🤪 改行さえせずに:
result = dplyr::summarize(dplyr::group_by(dplyr::filter(dplyr::select(diamonds, carat, cut, price), carat > 1), cut), mean(price))
論理の流れとプログラムの流れが合わず、目が行ったり来たり。
さっきのほうがぜんぜんマシ。
パイプ演算子 |> を使おう
😁 慣れれば、論理の流れを追いやすい:
result = diamonds |>
dplyr::select(carat, cut, price) |> # 列を抽出して
dplyr::filter(carat > 1) |> # 行を抽出して
dplyr::group_by(cut) |> # グループ化して
dplyr::summarize(mean(price)) |> # 平均を計算
print() # 表示してみる
cut mean(price)
1 Fair 7177.856
2 Good 7753.601
3 Very Good 8340.549
4 Premium 8487.249
5 Ideal 8674.227
tidyverseパッケージ群はこういう使い方をしやすい設計。
使わなければならないわけではないが、読めたほうがいい。
R < 4.2 までよく使われていた %>% もほぼ同じ。
列の抽出: select()
列の番号で指定:
result = diamonds |>
dplyr::select(1, 2, 7) |>
print()
carat cut price
1 0.23 Ideal 326
2 0.21 Premium 326
3 0.23 Good 327
4 0.29 Premium 334
--
53937 0.72 Good 2757
53938 0.70 Very Good 2757
53939 0.86 Premium 2757
53940 0.75 Ideal 2757
別解: |> dplyr::select(c(1, 2, 7)), diamonds[, c(1, 2, 7)]
🔰 starwars の 1, 10, 11 列目を3通りの方法で抽出してみよう
列の抽出: select()
列の名前で指定:
result = diamonds |>
dplyr::select(carat, cut, price) |>
print()
carat cut price
1 0.23 Ideal 326
2 0.21 Premium 326
3 0.23 Good 327
4 0.29 Premium 334
--
53937 0.72 Good 2757
53938 0.70 Very Good 2757
53939 0.86 Premium 2757
53940 0.75 Ideal 2757
別解: |> dplyr::select(c("carat", "cut", "price"))
🔰 starwars の 1, 10, 11 列目を列名で抽出してみよう
列の抽出: select()
捨てる列を反転指定:
result = diamonds |>
dplyr::select(!c(carat, cut, price)) |>
print()
color clarity depth table x y z
1 E SI2 61.5 55 3.95 3.98 2.43
2 E SI1 59.8 61 3.89 3.84 2.31
3 E VS1 56.9 65 4.05 4.07 2.31
4 I VS2 62.4 58 4.20 4.23 2.63
--
53937 D SI1 63.1 55 5.69 5.75 3.61
53938 D SI1 62.8 60 5.66 5.68 3.56
53939 H SI2 61.0 58 6.15 6.12 3.74
53940 D SI2 62.2 55 5.83 5.87 3.64
別解: |> dplyr::select(!c("carat", "cut", "price"))
🔰 starwars の 1, 10, 11 列目を除外してみよう
列の抽出: select()
名前の部分一致で指定:
result = diamonds |>
dplyr::select(starts_with("c")) |>
print()
carat cut color clarity
1 0.23 Ideal E SI2
2 0.21 Premium E SI1
3 0.23 Good E VS1
4 0.29 Premium I VS2
--
53937 0.72 Good D SI1
53938 0.70 Very Good D SI1
53939 0.86 Premium H SI2
53940 0.75 Ideal D SI2
See ?dplyr_tidy_select or selection helpers for more details.
🔰 starwars の “s” で終わる列を抽出してみよう
列の抽出: select()
列の型で指定:
result = diamonds |>
dplyr::select(where(is.numeric)) |>
print()
carat depth table price x y z
1 0.23 61.5 55 326 3.95 3.98 2.43
2 0.21 59.8 61 326 3.89 3.84 2.31
3 0.23 56.9 65 327 4.05 4.07 2.31
4 0.29 62.4 58 334 4.20 4.23 2.63
--
53937 0.72 63.1 55 2757 5.69 5.75 3.61
53938 0.70 62.8 60 2757 5.66 5.68 3.56
53939 0.86 61.0 58 2757 6.15 6.12 3.74
53940 0.75 62.2 55 2757 5.83 5.87 3.64
See ?dplyr_tidy_select or tidyselect::where for more details.
🔰 starwars の文字列型の列を抽出してみよう
行の抽出: filter()
等号 == で完全一致する行のみ残す:
result = diamonds |>
dplyr::filter(cut == "Ideal") |>
print()
carat cut color clarity depth table price x y z
1 0.23 Ideal E SI2 61.5 55 326 3.95 3.98 2.43
2 0.23 Ideal J VS1 62.8 56 340 3.93 3.90 2.46
3 0.31 Ideal J SI2 62.2 54 344 4.35 4.37 2.71
4 0.30 Ideal I SI2 62.0 54 348 4.31 4.34 2.68
--
21548 0.71 Ideal E SI1 61.9 56 2756 5.71 5.73 3.54
21549 0.71 Ideal G VS1 61.4 56 2756 5.76 5.73 3.53
21550 0.72 Ideal D SI1 60.8 57 2757 5.75 5.76 3.50
21551 0.75 Ideal D SI2 62.2 55 2757 5.83 5.87 3.64
別解: diamonds[diamonds[["cut"]] == "Ideal", ]
🔰 starwars の人間を抽出してみよう
行の抽出: filter()
不等号 !=, <, <=, >, >= を満たす行のみ残す:
result = diamonds |>
dplyr::filter(cut != "Ideal") |>
print()
carat cut color clarity depth table price x y z
1 0.21 Premium E SI1 59.8 61 326 3.89 3.84 2.31
2 0.23 Good E VS1 56.9 65 327 4.05 4.07 2.31
3 0.29 Premium I VS2 62.4 58 334 4.20 4.23 2.63
4 0.31 Good J SI2 63.3 58 335 4.34 4.35 2.75
--
32386 0.72 Premium D SI1 62.7 59 2757 5.69 5.73 3.58
32387 0.72 Good D SI1 63.1 55 2757 5.69 5.75 3.61
32388 0.70 Very Good D SI1 62.8 60 2757 5.66 5.68 3.56
32389 0.86 Premium H SI2 61.0 58 2757 6.15 6.12 3.74
🔰 starwars の身長が150以下のキャラクタを抽出してみよう
行の抽出: filter()
複数の値のうちどれかに一致する行のみ残す:
result = diamonds |>
dplyr::filter(cut %in% c("Ideal", "Good")) |>
print()
carat cut color clarity depth table price x y z
1 0.23 Ideal E SI2 61.5 55 326 3.95 3.98 2.43
2 0.23 Good E VS1 56.9 65 327 4.05 4.07 2.31
3 0.31 Good J SI2 63.3 58 335 4.34 4.35 2.75
4 0.30 Good J SI1 64.0 55 339 4.25 4.28 2.73
--
26454 0.71 Ideal G VS1 61.4 56 2756 5.76 5.73 3.53
26455 0.72 Ideal D SI1 60.8 57 2757 5.75 5.76 3.50
26456 0.72 Good D SI1 63.1 55 2757 5.69 5.75 3.61
26457 0.75 Ideal D SI2 62.2 55 2757 5.83 5.87 3.64
🔰 starwars の目の色が青か赤のキャラクタを抽出してみよう
行の抽出: filter()
2つの条件を両方満たす行のみ残す (AND):
result = diamonds |>
dplyr::filter(carat > 2 & price < 14000) |>
print()
carat cut color clarity depth table price x y z
1 2.06 Premium J I1 61.2 58 5203 8.10 8.07 4.95
2 2.14 Fair J I1 69.4 57 5405 7.74 7.70 5.36
3 2.15 Fair J I1 65.5 57 5430 8.01 7.95 5.23
4 2.22 Fair J I1 66.7 56 5607 8.04 8.02 5.36
--
641 2.07 Premium H SI1 62.7 58 13993 8.14 8.09 5.09
642 2.07 Good I SI1 63.6 58 13993 8.09 7.99 5.11
643 2.13 Very Good J SI1 62.8 58 13996 8.13 8.17 5.12
644 2.11 Premium J SI1 62.4 58 13996 8.27 8.17 5.13
🔰 starwars のタトゥーイン生まれの人間を抽出してみよう
行の抽出: filter()
2つの条件のいずれかを満たす行のみ残す (OR):
result = diamonds |>
dplyr::filter(carat > 2 | price < 14000) |>
print()
carat cut color clarity depth table price x y z
1 0.23 Ideal E SI2 61.5 55 326 3.95 3.98 2.43
2 0.21 Premium E SI1 59.8 61 326 3.89 3.84 2.31
3 0.23 Good E VS1 56.9 65 327 4.05 4.07 2.31
4 0.29 Premium I VS2 62.4 58 334 4.20 4.23 2.63
--
53023 0.72 Good D SI1 63.1 55 2757 5.69 5.75 3.61
53024 0.70 Very Good D SI1 62.8 60 2757 5.66 5.68 3.56
53025 0.86 Premium H SI2 61.0 58 2757 6.15 6.12 3.74
53026 0.75 Ideal D SI2 62.2 55 2757 5.83 5.87 3.64
🔰 starwars の身長200以上または体重100以上のキャラを抽出しよう
上位/下位の行の抽出: slice_max(), slice_min()
指定した列の値が大きい順に n 行または割合 prop で抽出:
result = diamonds |>
dplyr::slice_max(price, n = 5L) |>
print()
carat cut color clarity depth table price x y z
1 2.29 Premium I VS2 60.8 60 18823 8.50 8.47 5.16
2 2.00 Very Good G SI1 63.5 56 18818 7.90 7.97 5.04
3 1.51 Ideal G IF 61.7 55 18806 7.37 7.41 4.56
4 2.07 Ideal G SI2 62.5 55 18804 8.20 8.13 5.11
5 2.00 Very Good H SI1 62.8 57 18803 7.95 8.00 5.01
割合を指定するなら n の代わりに prop = 0.05
🔰 starwars の身長が低い順に5名だけ抽出してみよう
上位/下位の行の抽出: slice_max(), slice_min()
指定した列の値が大きい順に各グループから抽出:
result = diamonds |>
dplyr::group_by(cut) |>
dplyr::slice_max(price, n = 2L) |>
print()
carat cut color clarity depth table price x y z
1 2.01 Fair G SI1 70.6 64 18574 7.43 6.64 4.69
2 2.02 Fair H VS2 64.5 57 18565 8.00 7.95 5.14
3 2.80 Good G SI2 63.8 58 18788 8.90 8.85 0.00
4 2.07 Good I VS2 61.8 61 18707 8.12 8.16 5.03
--
7 2.29 Premium I VS2 60.8 60 18823 8.50 8.47 5.16
8 2.29 Premium I SI1 61.8 59 18797 8.52 8.45 5.24
9 1.51 Ideal G IF 61.7 55 18806 7.37 7.41 4.56
10 2.07 Ideal G SI2 62.5 55 18804 8.20 8.13 5.11
🔰 starwars のジェンダーごとに身長が低い3名ずつ抽出してみよう
先頭/末尾の行の抽出: slice_head(), slice_tail()
各グループの先頭を n 行または割合 prop で抽出:
result = diamonds |>
dplyr::group_by(cut) |>
dplyr::slice_head(n = 3L) |>
print()
carat cut color clarity depth table price x y z
1 0.22 Fair E VS2 65.1 61 337 3.87 3.78 2.49
2 0.86 Fair E SI2 55.1 69 2757 6.45 6.33 3.52
3 0.96 Fair F SI2 66.3 62 2759 6.27 5.95 4.07
4 0.23 Good E VS1 56.9 65 327 4.05 4.07 2.31
--
12 0.22 Premium F SI1 60.4 61 342 3.88 3.84 2.33
13 0.23 Ideal E SI2 61.5 55 326 3.95 3.98 2.43
14 0.23 Ideal J VS1 62.8 56 340 3.93 3.90 2.46
15 0.31 Ideal J SI2 62.2 54 344 4.35 4.37 2.71
🔰 starwars のジェンダーごとに先頭3名ずつ抽出してみよう
そのほかの slice*() 系
ランダムに n 行または割合 prop でサンプル:
result = diamonds |>
dplyr::group_by(cut) |>
dplyr::slice_sample(n = 3L, replace = FALSE) |>
print()
carat cut color clarity depth table price x y z
1 0.45 Fair F SI1 66.8 59 794 4.79 4.63 3.16
2 0.90 Fair E SI2 65.8 58 3084 6.02 5.98 3.95
3 2.00 Fair J VS2 65.4 58 11966 7.96 7.75 5.14
4 2.18 Good H SI2 60.4 64 16690 8.38 8.47 5.09
--
12 0.80 Premium G SI2 61.4 56 2451 5.99 5.96 3.67
13 1.58 Ideal E VS2 62.7 56 15579 7.45 7.55 4.70
14 0.53 Ideal F VVS2 62.7 56 2030 5.16 6.20 3.25
15 1.10 Ideal G VVS2 60.5 56 9215 6.76 6.70 4.07
任意のX番目の行を抽出: dplyr::slice(X)
要約・集計: summarize()
列の合計、平均、最大などを求める:
result = diamonds |>
dplyr::summarize(sum(carat), mean(carat), max(price)) |>
print()
sum(carat) mean(carat) max(price)
1 43040.87 0.7979397 18823
vectorを受け取って1つの値を返す集約関数:
min(), max(), mean(), median(), var(), sd(), etc.
🔰 mpg の市街地(cty)と高速道路(hwy)の燃費平均値を計算しよう
要約・集計: summarize()
列の値をグループごとに集計する:
result = diamonds |>
dplyr::group_by(cut) |>
dplyr::summarize(avg_carat = mean(carat),
max_price = max(price)) |>
print()
cut avg_carat max_price
1 Fair 1.0461366 18574
2 Good 0.8491847 18788
3 Very Good 0.8063814 18818
4 Premium 0.8919549 18823
5 Ideal 0.7028370 18806
🔰 mpg の燃費平均値を駆動方式(drv)ごとに計算しよう
要約・集計: summarize(across())
複数の列の値をまとめて集計する:
result = diamonds |>
dplyr::group_by(cut) |>
dplyr::summarize(across(where(is.numeric), mean)) |>
print()
cut carat depth table price x y z
1 Fair 1.0461366 64.04168 59.05379 4358.758 6.246894 6.182652 3.982770
2 Good 0.8491847 62.36588 58.69464 3928.864 5.838785 5.850744 3.639507
3 Very Good 0.8063814 61.81828 57.95615 3981.760 5.740696 5.770026 3.559801
4 Premium 0.8919549 61.26467 58.74610 4584.258 5.973887 5.944879 3.647124
5 Ideal 0.7028370 61.70940 55.95167 3457.542 5.507451 5.520080 3.401448
🔰 mpg の各数値列の最大値を駆動方式ごとに計算しよう
要約・集計: reframe()
複数の値を返す関数で集約すると、結果は複数行にまたがる:
quantile(diamonds$price)
0% 25% 50% 75% 100%
326.00 950.00 2401.00 5324.25 18823.00
result = diamonds |>
dplyr::reframe(across(where(is.numeric), quantile)) |>
print()
carat depth table price x y z
1 0.20 43.0 43 326.00 0.00 0.00 0.00
2 0.40 61.0 56 950.00 4.71 4.72 2.91
3 0.70 61.8 57 2401.00 5.70 5.71 3.53
4 1.04 62.5 59 5324.25 6.54 6.54 4.04
5 5.01 79.0 95 18823.00 10.74 58.90 31.80
🔰 mpg の各数値列の range() を駆動方式ごとに計算しよう
要約・集計: count()
指定した列の組み合わせ出現数を数える:
result = diamonds |>
dplyr::count(cut, color) |>
print()
cut color n
1 Fair D 163
2 Fair E 224
3 Fair F 312
4 Fair G 314
--
32 Ideal G 4884
33 Ideal H 3115
34 Ideal I 2093
35 Ideal J 896
🔰 starwars の性とジェンダーの組み合わせを数えてみよう
重複行の除去: distinct()
指定した列に関してユニークな行のみ残す:
result = diamonds |>
dplyr::distinct(cut, color) |>
print()
cut color
1 Ideal E
2 Premium E
3 Good E
4 Premium I
--
32 Fair G
33 Fair J
34 Fair I
35 Fair D
.keep_all = TRUE
オプションを付けると指定しなかった列も残せる。
🔰 starwars の性とジェンダーの組み合わせだけ残してみよう
行の並べ替え: arrange()
指定した列の昇順(または降順 desc())で行を並べ替える:
result = diamonds |>
dplyr::arrange(color, desc(carat)) |> # 色の昇順。色が同じなら大きさ降順
print()
carat cut color clarity depth table price x y z
1 3.40 Fair D I1 66.8 52 15964 9.42 9.34 6.27
2 2.75 Ideal D I1 60.9 57 13156 9.04 8.98 5.49
3 2.58 Very Good D SI2 58.9 63 14749 9.08 9.01 5.33
4 2.57 Premium D SI2 58.9 58 17924 8.99 8.94 5.28
--
53937 0.27 Very Good J VVS2 60.8 57 443 4.16 4.20 2.54
53938 0.24 Very Good J VVS2 62.8 57 336 3.94 3.96 2.48
53939 0.24 Ideal J VVS2 62.8 57 432 3.96 3.94 2.48
53940 0.23 Ideal J VS1 62.8 56 340 3.93 3.90 2.46
🔰 starwars の種族と身長で並べ替えてみよう
列の並べ替え: relocate()
指定した列を左端に移動:
result = diamonds |>
dplyr::relocate(carat, price, clarity) |>
print()
carat price clarity cut color depth table x y z
1 0.23 326 SI2 Ideal E 61.5 55 3.95 3.98 2.43
2 0.21 326 SI1 Premium E 59.8 61 3.89 3.84 2.31
3 0.23 327 VS1 Good E 56.9 65 4.05 4.07 2.31
4 0.29 334 VS2 Premium I 62.4 58 4.20 4.23 2.63
--
53937 0.72 2757 SI1 Good D 63.1 55 5.69 5.75 3.61
53938 0.70 2757 SI1 Very Good D 62.8 60 5.66 5.68 3.56
53939 0.86 2757 SI2 Premium H 61.0 58 6.15 6.12 3.74
53940 0.75 2757 SI2 Ideal D 62.2 55 5.83 5.87 3.64
.before, .after オプションで微調整も可能。
🔰 starwars の種族と出身地を名前の右に移動してみよう
列の追加・変更: mutate()
既存の列名を指定すると上書き:
result = diamonds |>
dplyr::mutate(ratio = price / carat,
price = 105.59 * price) |>
print()
carat cut color clarity depth table price x y z ratio
1 0.23 Ideal E SI2 61.5 55 34422.34 3.95 3.98 2.43 1417.391
2 0.21 Premium E SI1 59.8 61 34422.34 3.89 3.84 2.31 1552.381
3 0.23 Good E VS1 56.9 65 34527.93 4.05 4.07 2.31 1421.739
4 0.29 Premium I VS2 62.4 58 35267.06 4.20 4.23 2.63 1151.724
--
53937 0.72 Good D SI1 63.1 55 291111.63 5.69 5.75 3.61 3829.167
53938 0.70 Very Good D SI1 62.8 60 291111.63 5.66 5.68 3.56 3938.571
53939 0.86 Premium H SI2 61.0 58 291111.63 6.15 6.12 3.74 3205.814
53940 0.75 Ideal D SI2 62.2 55 291111.63 5.83 5.87 3.64 3676.000
🔰 starwars の身長をメートルで表してBMIを計算してみよう
列名の変更: rename()
new = old の形で指定する:
result = diamonds |>
dplyr::rename(size = carat) |>
print()
size cut color clarity depth table price x y z
1 0.23 Ideal E SI2 61.5 55 326 3.95 3.98 2.43
2 0.21 Premium E SI1 59.8 61 326 3.89 3.84 2.31
3 0.23 Good E VS1 56.9 65 327 4.05 4.07 2.31
4 0.29 Premium I VS2 62.4 58 334 4.20 4.23 2.63
--
53937 0.72 Good D SI1 63.1 55 2757 5.69 5.75 3.61
53938 0.70 Very Good D SI1 62.8 60 2757 5.66 5.68 3.56
53939 0.86 Premium H SI2 61.0 58 2757 6.15 6.12 3.74
53940 0.75 Ideal D SI2 62.2 55 2757 5.83 5.87 3.64
rename_with(diamonds, toupper) のように関数を渡すと一括変更。
🔰 starwars のheightをcmに、massをkgに改名してみよう
前処理は大きく2つに分けられる
- データ構造を対象とする処理 第3, 4回 本日の話題
- 使いたい部分だけ抽出
- グループごとに特徴を要約
- 何かの順に並べ替え 👈 第3回 ここまで紹介
- 異なるテーブルの結合
- 変形: 縦長 ↔ 横広
- データ内容を対象とする処理 — 第5回 来週
- 数値の変換: 対数、正規化
- 外れ値・欠損値への対処
- 型変換: 連続変数、カテゴリカル変数、指示変数、因子、日時
- 文字列処理: 正規表現によるパターンマッチ
憶えなくていい。公式サイトなどを見ながら作業
参考
- R for Data Science — Hadley Wickham et al.
- https://r4ds.hadley.nz, Paperback
- 日本語版書籍(Rではじめるデータサイエンス)
前処理大全 — 本橋智光
RユーザのためのRStudio[実践]入門 (宇宙船本) — 松村ら
- 整然データとは何か — @f_nisihara
- Speaker Deck, Colorless Green Ideas
- Other versions
- 「Rにやらせて楽しよう — データの可視化と下ごしらえ」 岩嵜航 2018
- 「Rを用いたデータ解析の基礎と応用」 石川由希 2024 名古屋大学