Rによるデータ前処理実習2021
(Graduate School of Life Sciences, Tohoku University)
- 入門1: 前処理とは。Rを使うメリット。Rの基本。
- 入門2: データ可視化の重要性と方法。
- データ構造の処理1: 抽出、集約など。
- データ構造の処理2: 結合、変形など。
- データ内容の処理: 数値、文字列、日時など。
- 実践: 現実の問題に対処してみる。
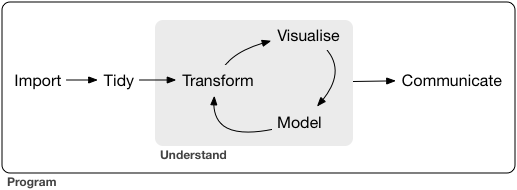
データ解析のおおまかな流れ
- コンピュータ環境の整備
- データの取得、読み込み
- 探索的データ解析
- 前処理、加工 (地味。意外と重い) 👈本実習の主題
- 可視化、仮説生成 (派手!楽しい!)
- 統計解析、仮説検証 (みんな勉強したがる)
- 報告、発表
そもそもなぜ解析? 生の数字見ればよくない?
生データは情報が多すぎて関係性も何も見えない
print(ggplot2::diamonds)
carat cut color clarity depth table price x y z
<dbl> <ord> <ord> <ord> <dbl> <dbl> <int> <dbl> <dbl> <dbl>
1 0.23 Ideal E SI2 61.5 55 326 3.95 3.98 2.43
2 0.21 Premium E SI1 59.8 61 326 3.89 3.84 2.31
3 0.23 Good E VS1 56.9 65 327 4.05 4.07 2.31
4 0.29 Premium I VS2 62.4 58 334 4.20 4.23 2.63
--
53937 0.72 Good D SI1 63.1 55 2757 5.69 5.75 3.61
53938 0.70 Very Good D SI1 62.8 60 2757 5.66 5.68 3.56
53939 0.86 Premium H SI2 61.0 58 2757 6.15 6.12 3.74
53940 0.75 Ideal D SI2 62.2 55 2757 5.83 5.87 3.64
ダイヤモンド53,940個について10項目の値を持つデータセット
要約統計量(平均とか分散とか)を見てみる
各列の平均とか標準偏差とか:
stat carat depth table price x y z
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 mean 0.80 61.75 57.46 3932.80 5.73 5.73 3.54
2 sd 0.47 1.43 2.23 3989.44 1.12 1.14 0.71
3 max 5.01 79.00 95.00 18823.00 10.74 58.90 31.80
大きさ carat と価格 price の相関係数は 0.92 (かなり高い)。
生のままよりは把握しやすいかも。
しかし要注意…
平均値ばかり見て可視化を怠ると構造を見逃す


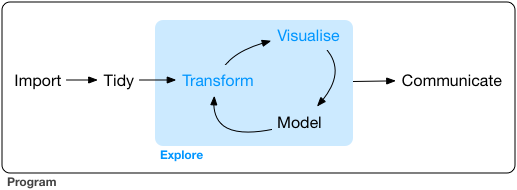
作図してみると全体像・構造が見やすい
情報の整理 → 正しい解析・新しい発見・仮説生成
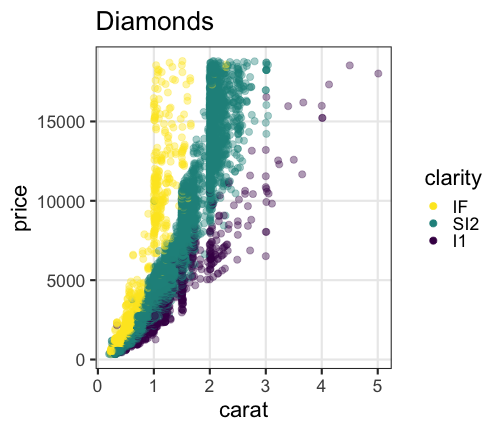
carat が大きいほど price も高いらしい。
その度合いは clarity によって異なるらしい。
作図してみると全体像・構造が見やすい
情報の整理 → 正しい解析・新しい発見・仮説生成
可視化だいじ。わかった。
でも「データ分析に費やす労力の8割は前処理」だって?
機械処理しやすい形 vs 人が読み書きしやすい形
- 作図や解析に使えるデータ形式はほぼ決まってる
ggplot(data, ...),glm(..., data, ...), …- 出発点となるデータはさまざま
- 実験ノート、フィールドノート、データベース、…
Happy families are all alike;
every unhappy family is unhappy in its own way
tidy datasets are all alike,
but every messy dataset is messy in its own way
整然データ tidy data vs 雑然データ messy data
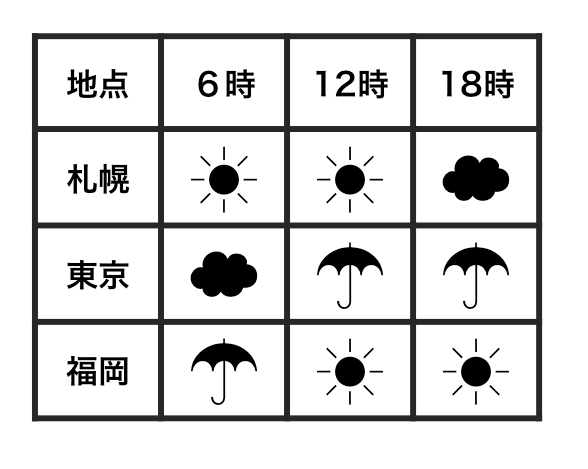
横1行は1つの観測
1セルは1つの値
整然データ tidy data vs 雑然データ messy data
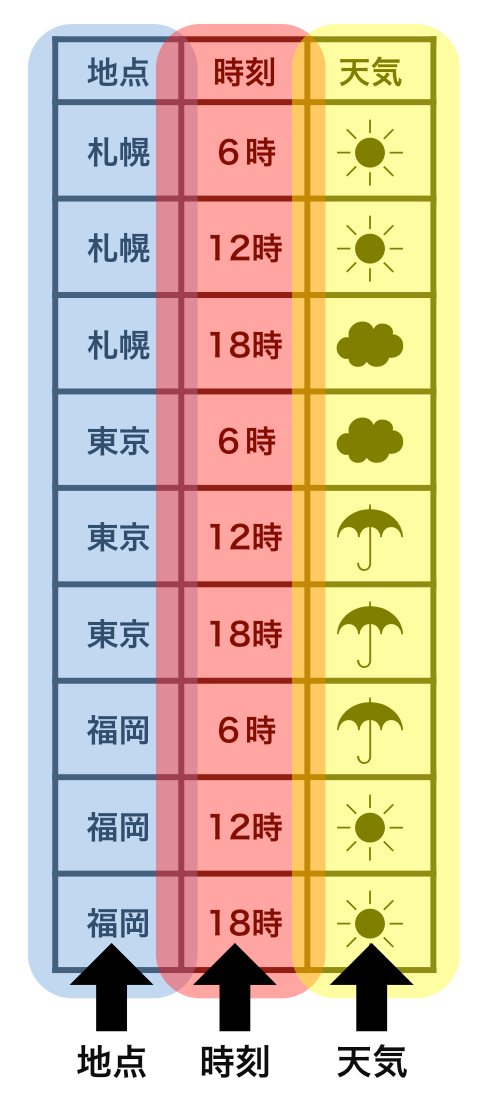
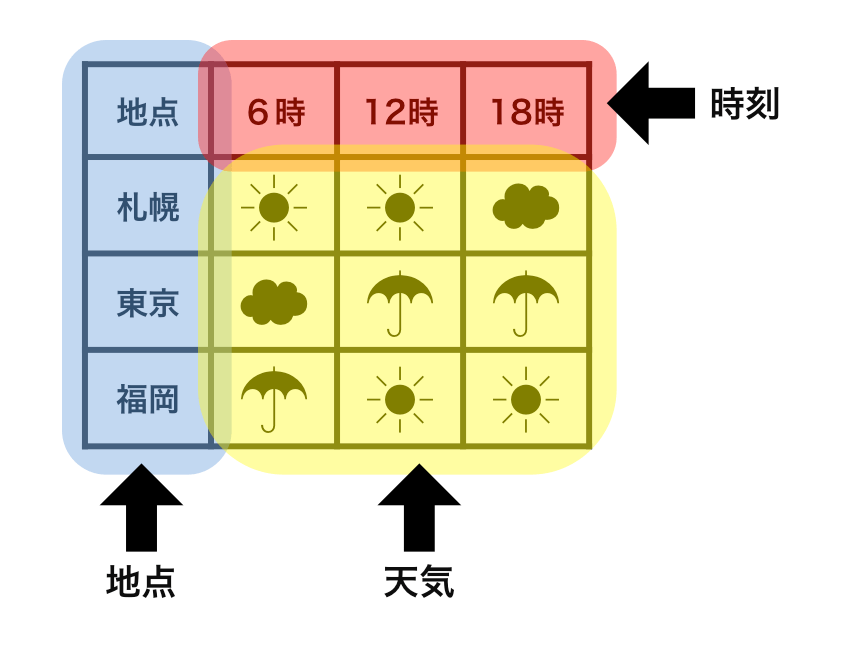
横1行は1つの観測
1セルは1つの値
整然データ tidy data vs 雑然データ messy data
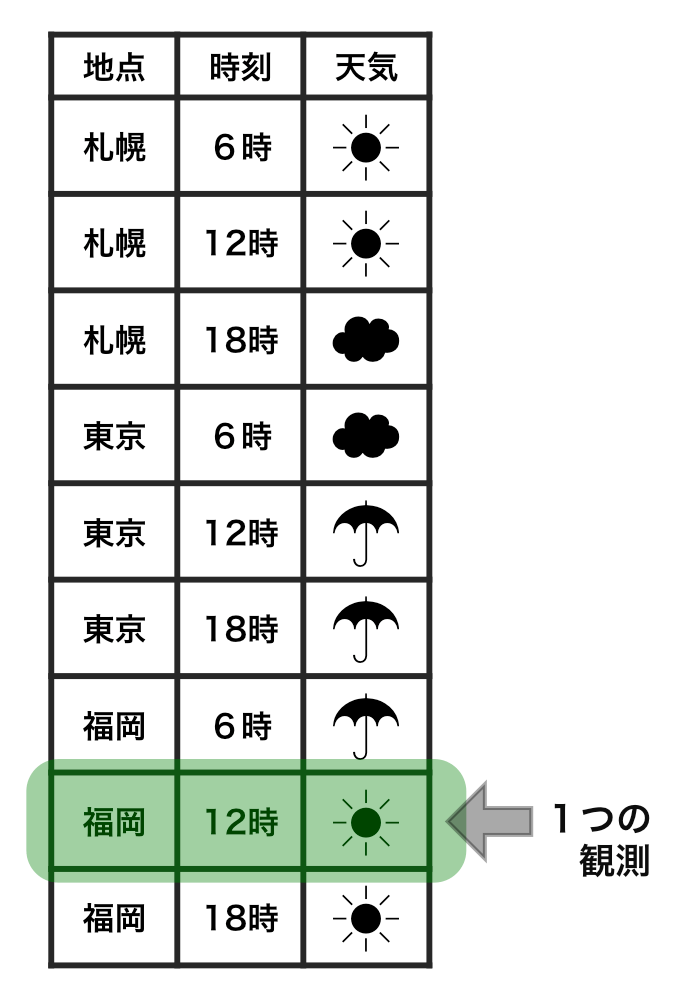
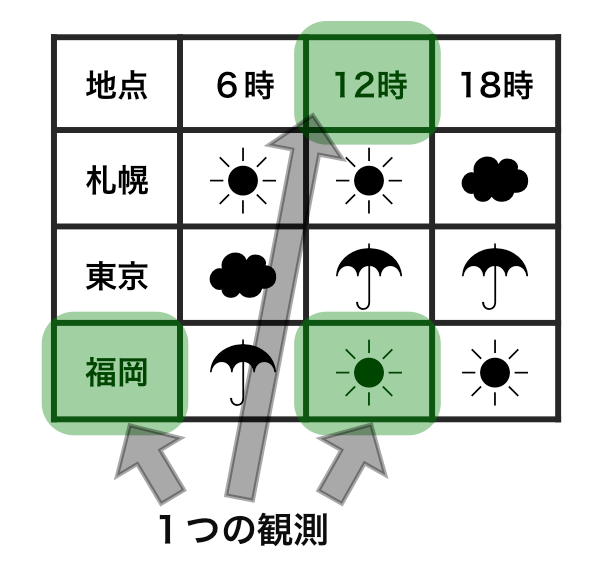
横1行は1つの観測
1セルは1つの値
整然データ tidy data vs 雑然データ messy data
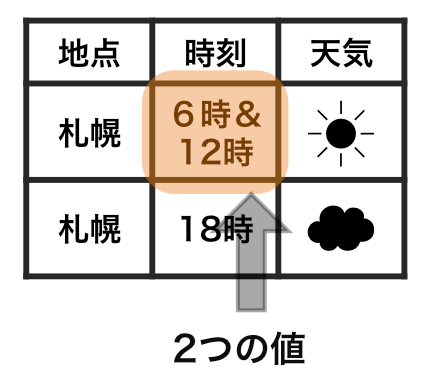
横1行は1つの観測
1セルは1つの値
整然データ tidy data
- 縦1列は1つの変数
- 横1行は1つの観測
- 1セルは1つの値
https://r4ds.had.co.nz/tidy-data.html
print(ggplot2::diamonds)
carat cut color clarity depth table price x y z
<dbl> <ord> <ord> <ord> <dbl> <dbl> <int> <dbl> <dbl> <dbl>
1 0.23 Ideal E SI2 61.5 55 326 3.95 3.98 2.43
2 0.21 Premium E SI1 59.8 61 326 3.89 3.84 2.31
3 0.23 Good E VS1 56.9 65 327 4.05 4.07 2.31
4 0.29 Premium I VS2 62.4 58 334 4.20 4.23 2.63
--
53937 0.72 Good D SI1 63.1 55 2757 5.69 5.75 3.61
53938 0.70 Very Good D SI1 62.8 60 2757 5.66 5.68 3.56
53939 0.86 Premium H SI2 61.0 58 2757 6.15 6.12 3.74
53940 0.75 Ideal D SI2 62.2 55 2757 5.83 5.87 3.64
整然データのご利益の例: ggplot2 (本日2時限目の話題)
x軸、y軸、色分け、パネル分けなどを列の名前で指定して簡単作図:
ggplot(diamonds) + aes(x = carat, y = price) +
geom_point(mapping = aes(color = color, size = clarity)) +
facet_wrap(vars(cut))
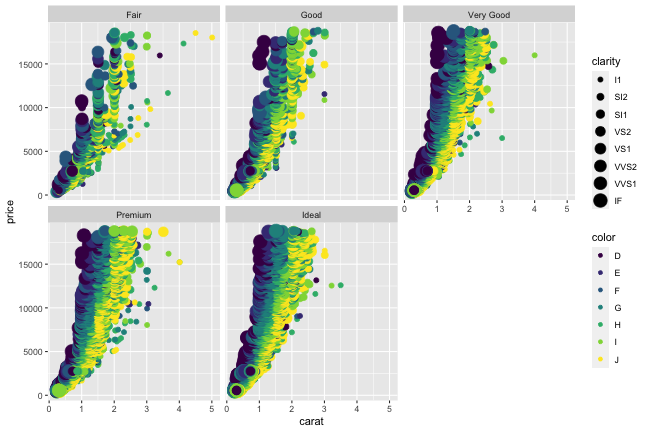
本日1時限目の話題
✅ データ解析全体の流れ。可視化だいじ (詳細は本日後半)
✅ 作図・解析の前にデータの前処理が必要 (詳細は明日)
⬜ なぜRを使うのか?
- 退屈な作業は機械にやらせてラクしよう
- 無料で誰でも使える
⬜ Rの基礎
Rを使わなかった場合の悲劇の例
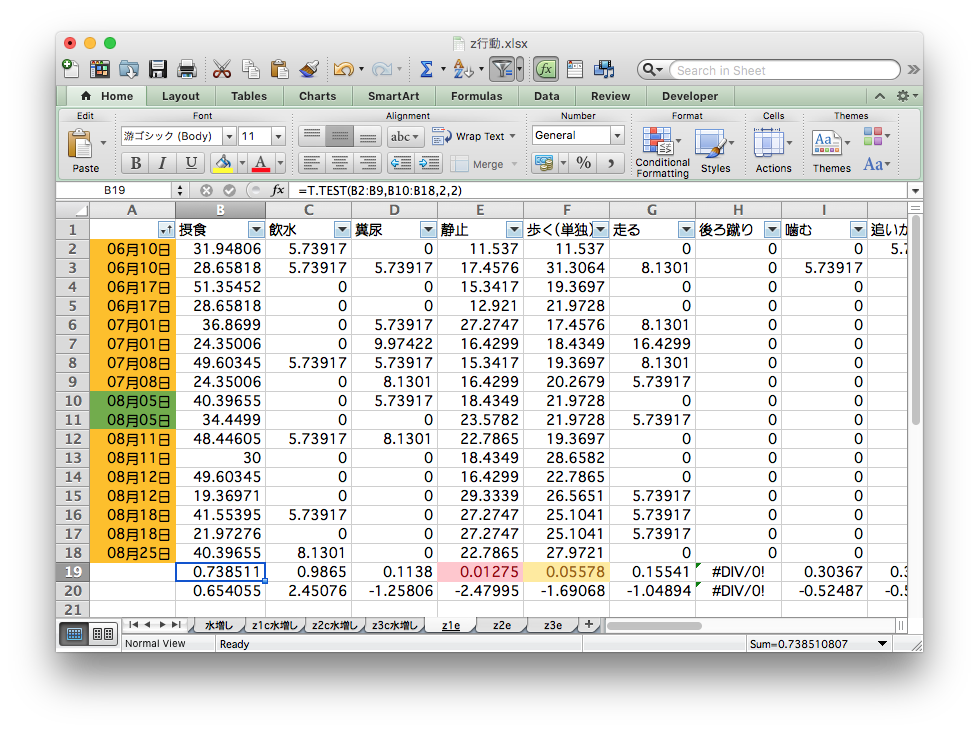
動物園の混合展示で、各種動物はどのように分布・行動しているか、
それらを決める要因は何か。膨大な観察データに基づく超大作卒論。
生データ: ここはまだそんなに悪くない
週に1回、各個体の位置と行動を種ごとのファイルに記録。
タブは個体、A列B列はXY座標でそれ以降の列は行動、各行はある時刻。
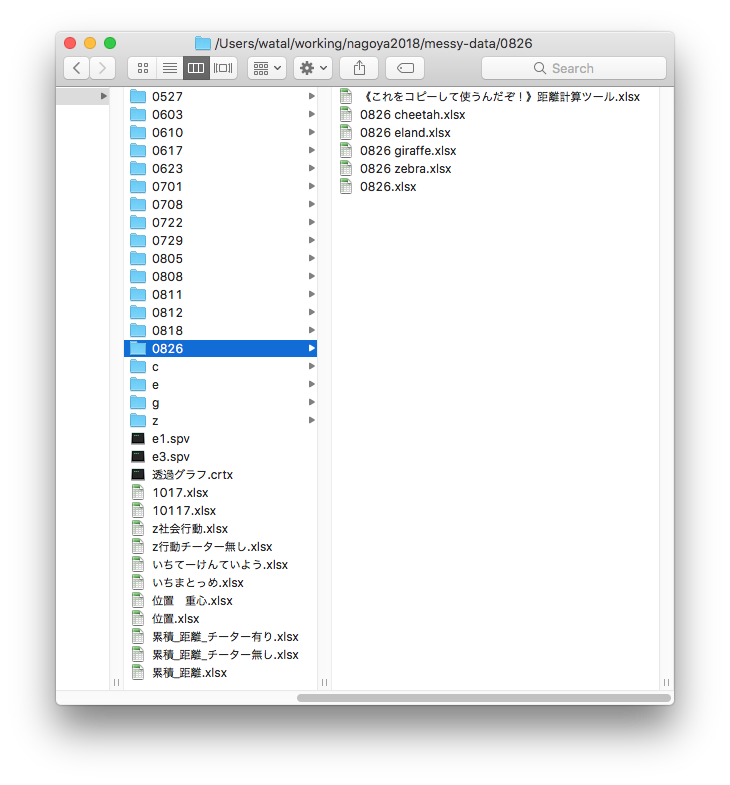
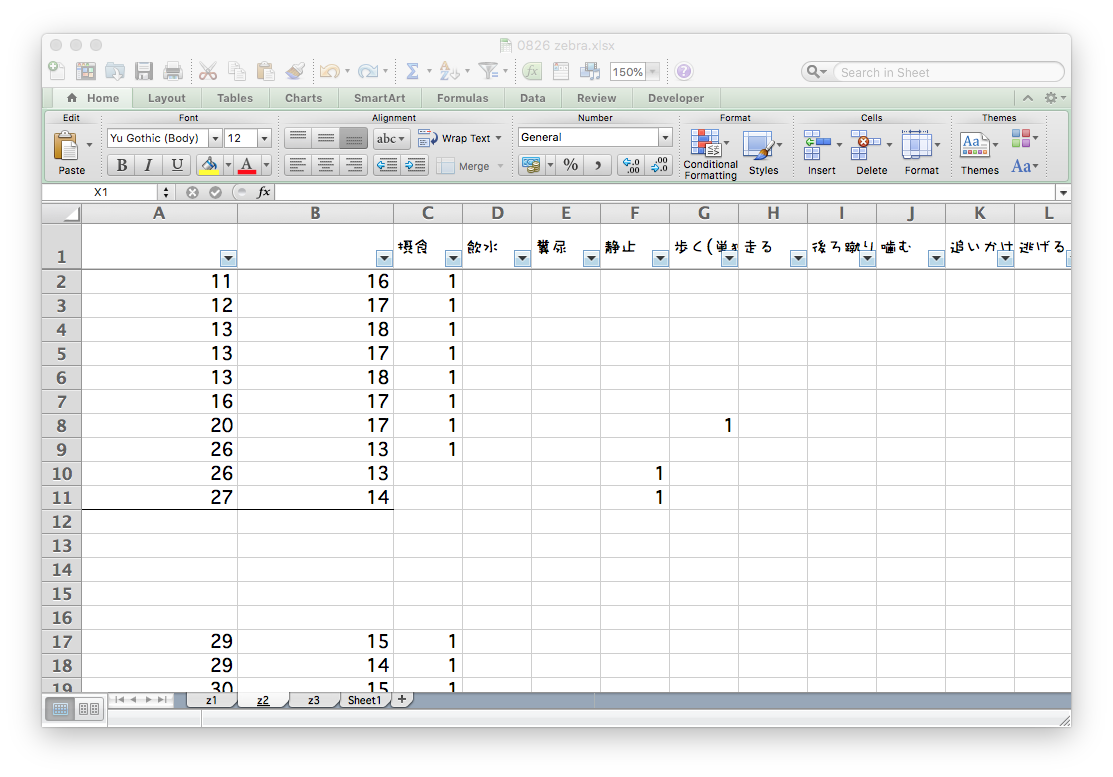
マウスとコピペを駆使して条件ごとに複製・集計
ちゃんと合ってるのかな… ファイルもタブもたくさん…
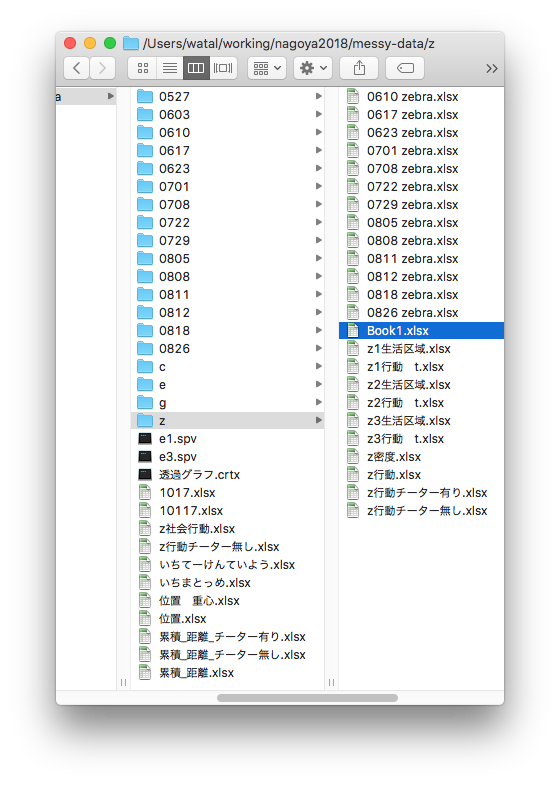
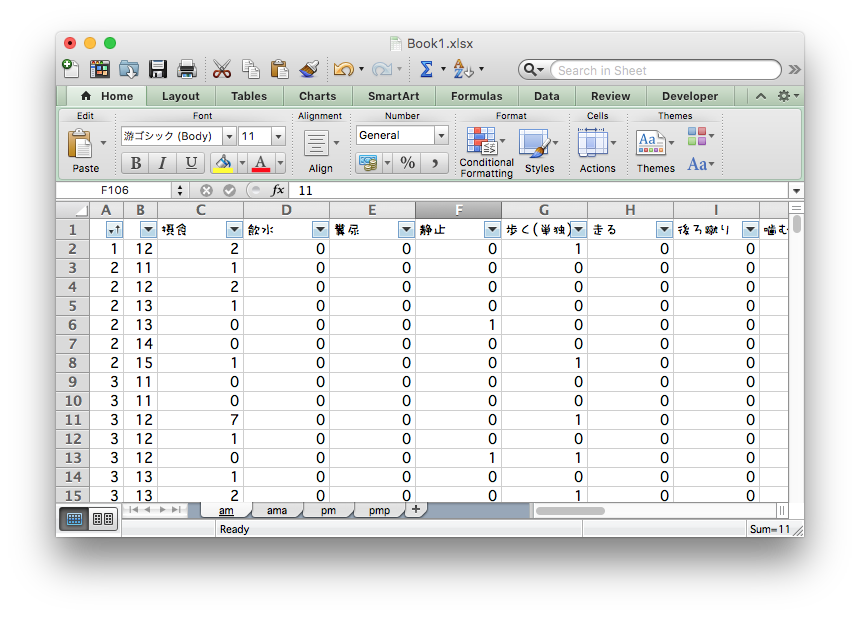
マウスとコピペを駆使して条件ごとに複製・集計
ちゃんと合ってるのかな… ファイルもタブもたくさん…
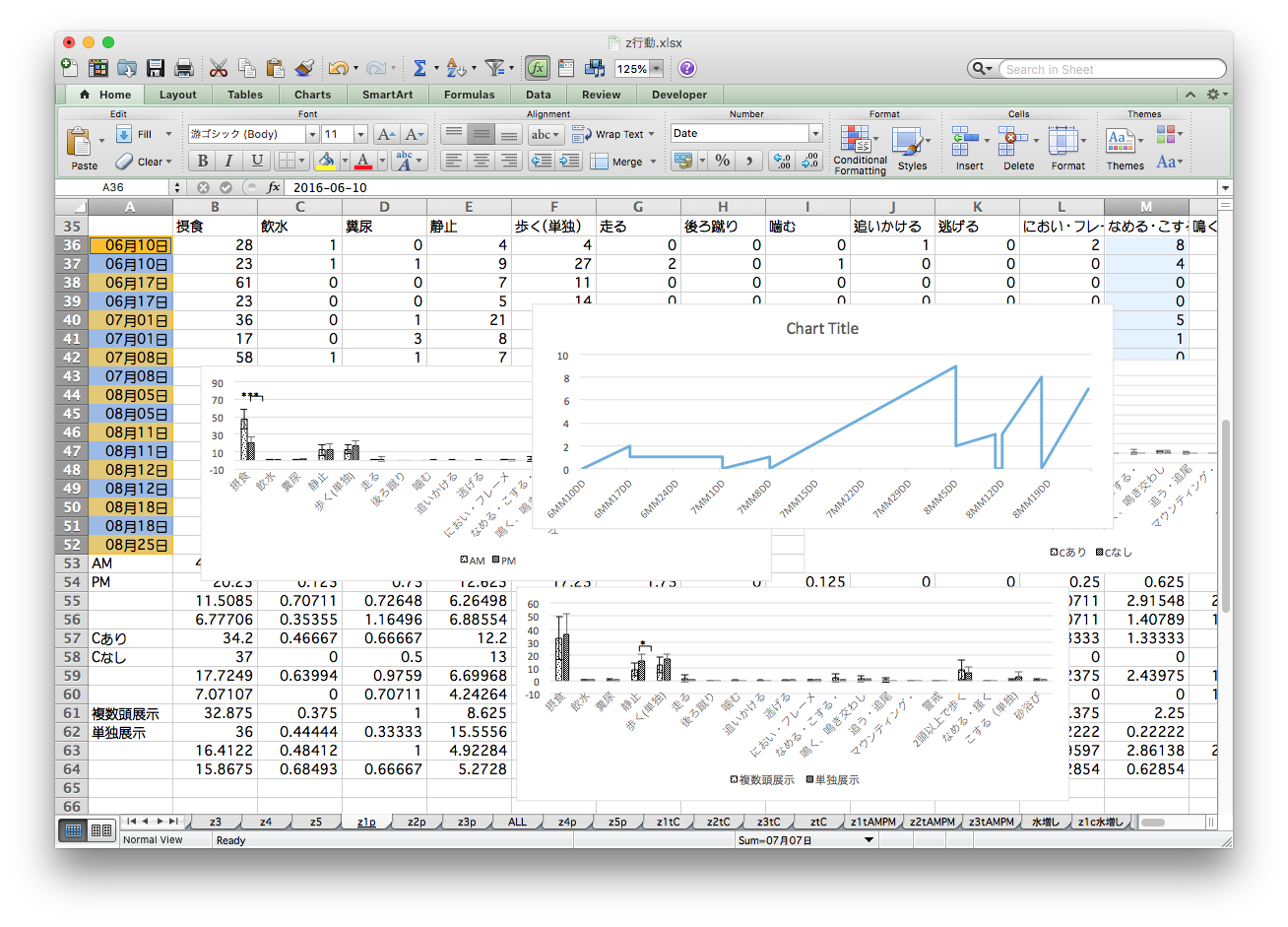
目と手で数え、濃淡を計算し、画像ソフトで塗る
泣きながら何十枚も…。無料期間が終わって今は使えない…。
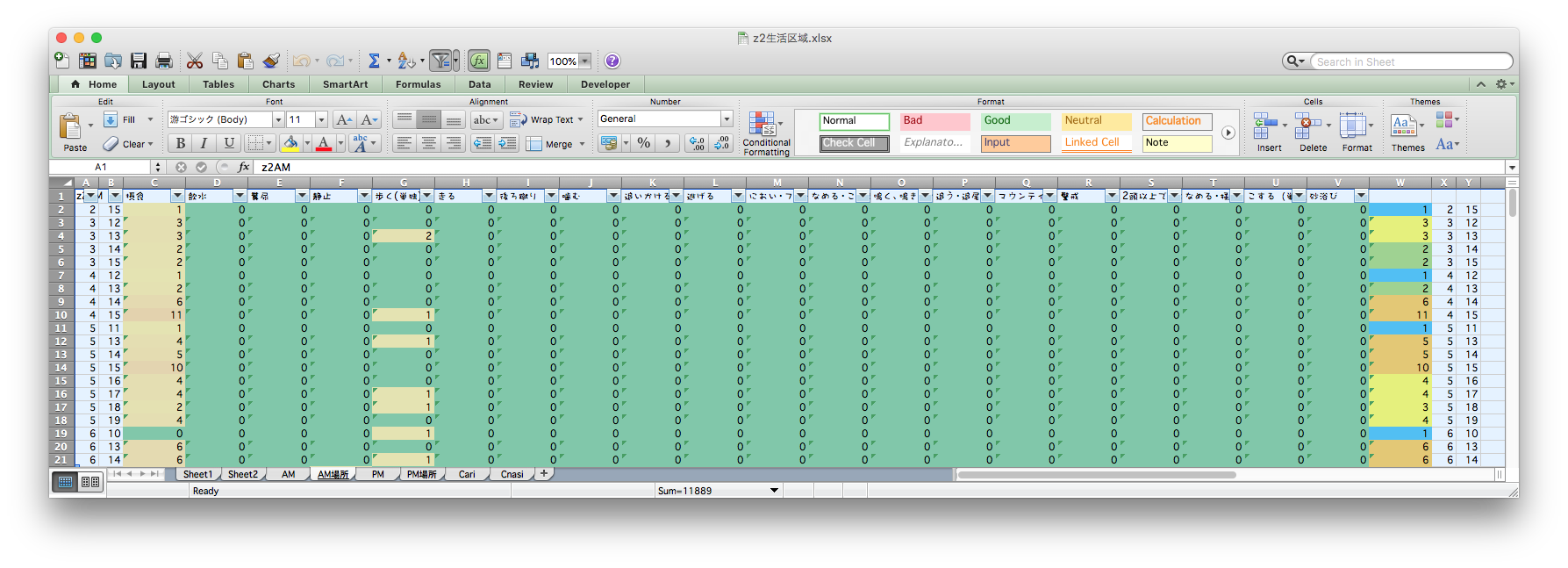
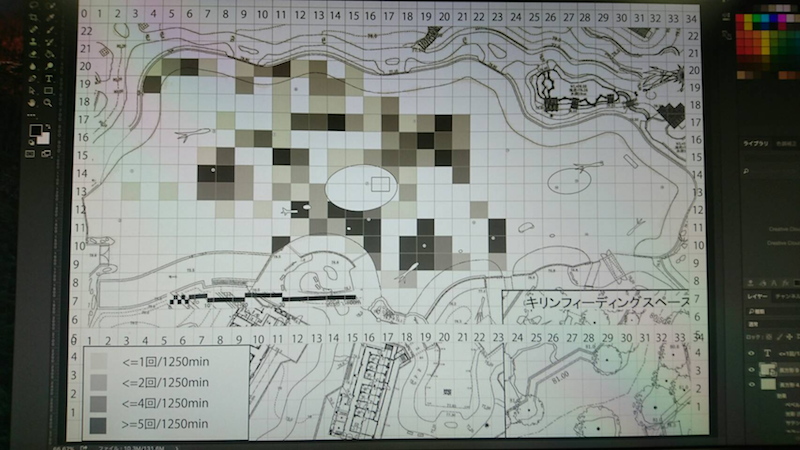
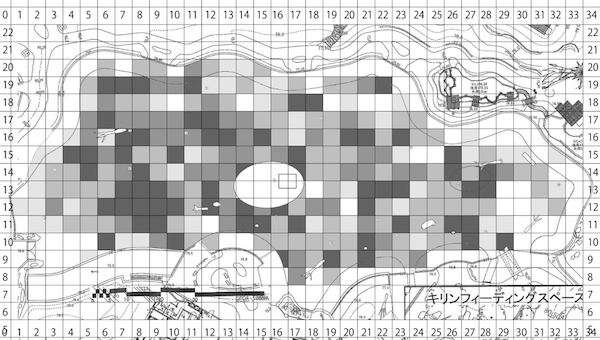
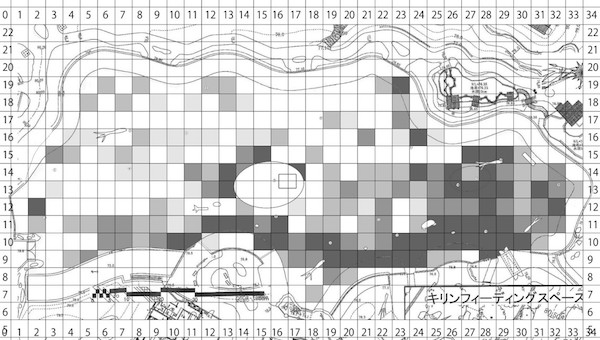
目作業・手作業 = シーシュポスの岩

- 膨大な単純作業がそもそもツラい
- 人間だもの、ミスは防ぎきれない
- ミスを減らすためのチェックもツラい
- ミスを発見 → 初めからやり直し
- 新データ追加 → 初めからやり直し
- 熟練してもツラいまま
- そのときの自分しかできない、記録に残らない
→ 検証のしようがない - 卒論なら努力賞でいいかもしれないけど、科学の手続きとしては問題。
プログラミングで大量のファイルを捌く
先の例に負けず生データはどっさり。でも頑張るのは機械。
こんな感じの図もRでラクラク描けるよ

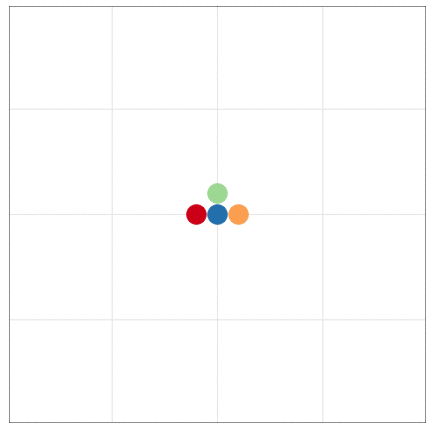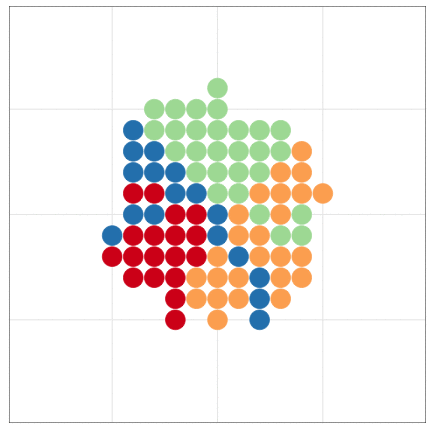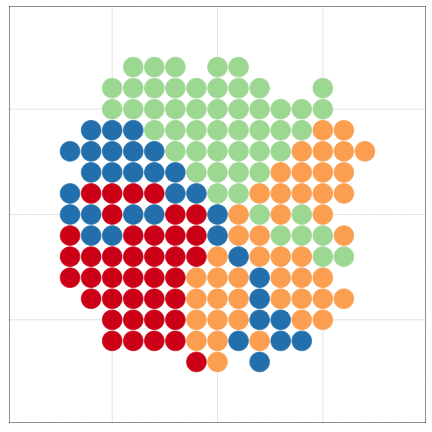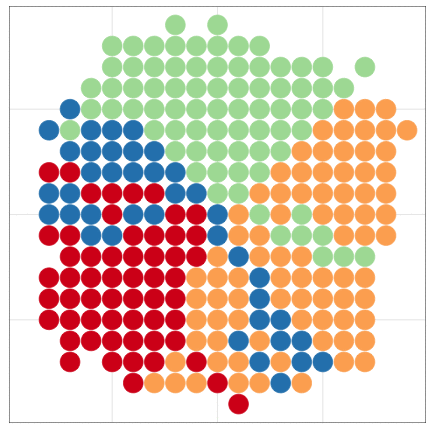
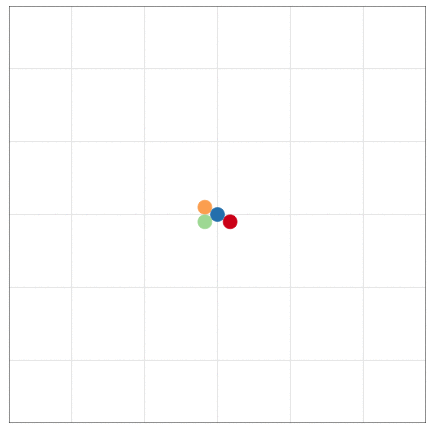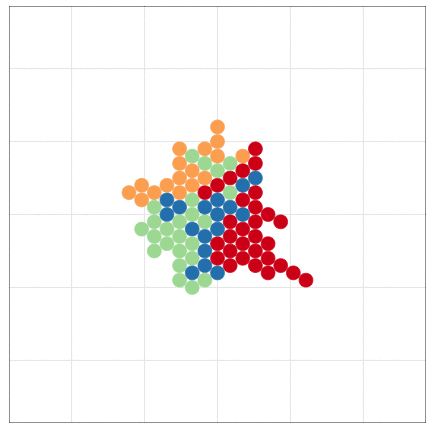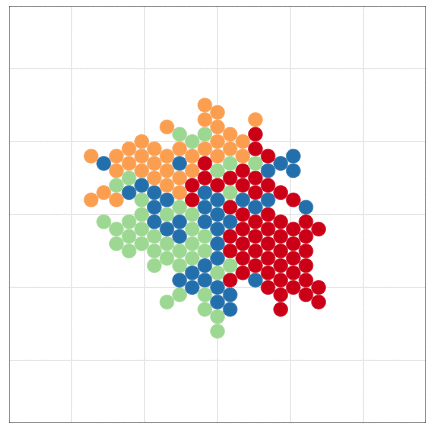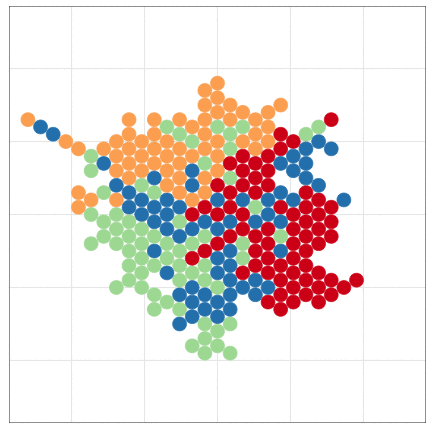
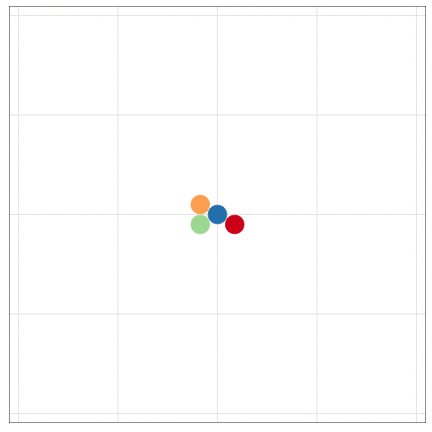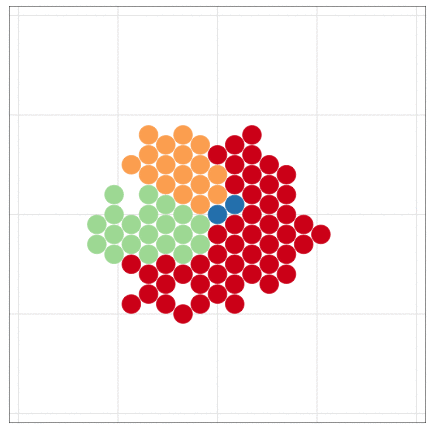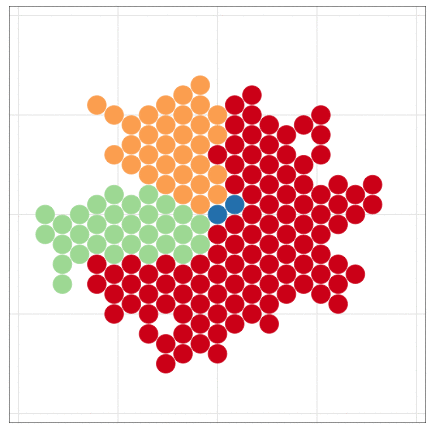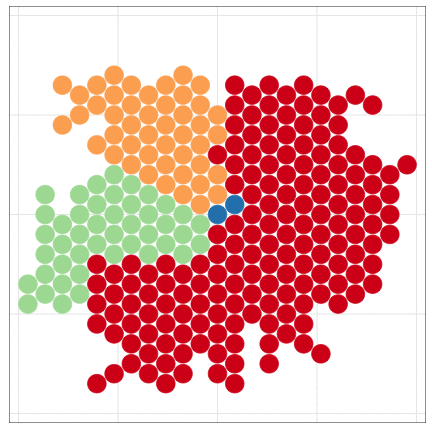
Rにやらせて楽しよう
- 規則性のある退屈な仕事は人間よりも機械のほうが得意。
- 一度書いたプログラムは、データが変わっても使いまわせる。
- 自分以外の人でも再現・検証できる
- きれいな図を簡単に描ける
- 部分的に改変しながらいろんな解析を試せる。
→ 仮説検証 だけでなく、 仮説生成(探索的データ解析) もやりやすい - やれば上達する。どんどん楽になる!
Rとは
統計解析と作図の機能が充実したプログラミング言語・環境

- クロスプラットフォーム
- Linux, Mac, Windows で動く
- オープンソース
- 永久に無償で、すべての機能を使える。
- 集合知によって常に進化している。
- コミュニティ
- 相談できる人や参考になるウェブサイトがたくさん見つかる。
本日1時限目の話題
✅ データ解析全体の流れ。可視化だいじ (詳細は本日後半)
✅ 作図・解析の前にデータの前処理が必要 (詳細は明日)
✅ なぜRを使うのか?
⬜ Rの基礎
- R環境のセットアップ
- Rとの対話
- 「プロジェクト」と「スクリプト」を作る
- 基本的な型と演算
- Rパッケージ
Keyboard shortcuts
| Action | ||
|---|---|---|
| Switch apps | commandtab | alttab |
| Quit apps | commandq | altF4 |
| Spotlight | commandspace | |
| Cut, Copy, Paste | commandx, -c, -v | ctrlx, -c, -v |
| Select all | commanda | ctrla |
| Undo | commandz | ctrlz |
| Find | commandf | ctrlf |
| Save | commands | ctrls |
R環境のセットアップ
- R本体
- コマンドを解釈して実行するコア部分。
- よく使われる関数なども標準パッケージとして同梱。
- RStudio Desktop
- Rをより快適に使うための総合開発環境 (IDE)
- 必須じゃないけど便利なので結構みんな使ってる。
RStudioを起動してConsoleで対話しよう
Workspace (Environment) = 一時オブジェクトの集まり
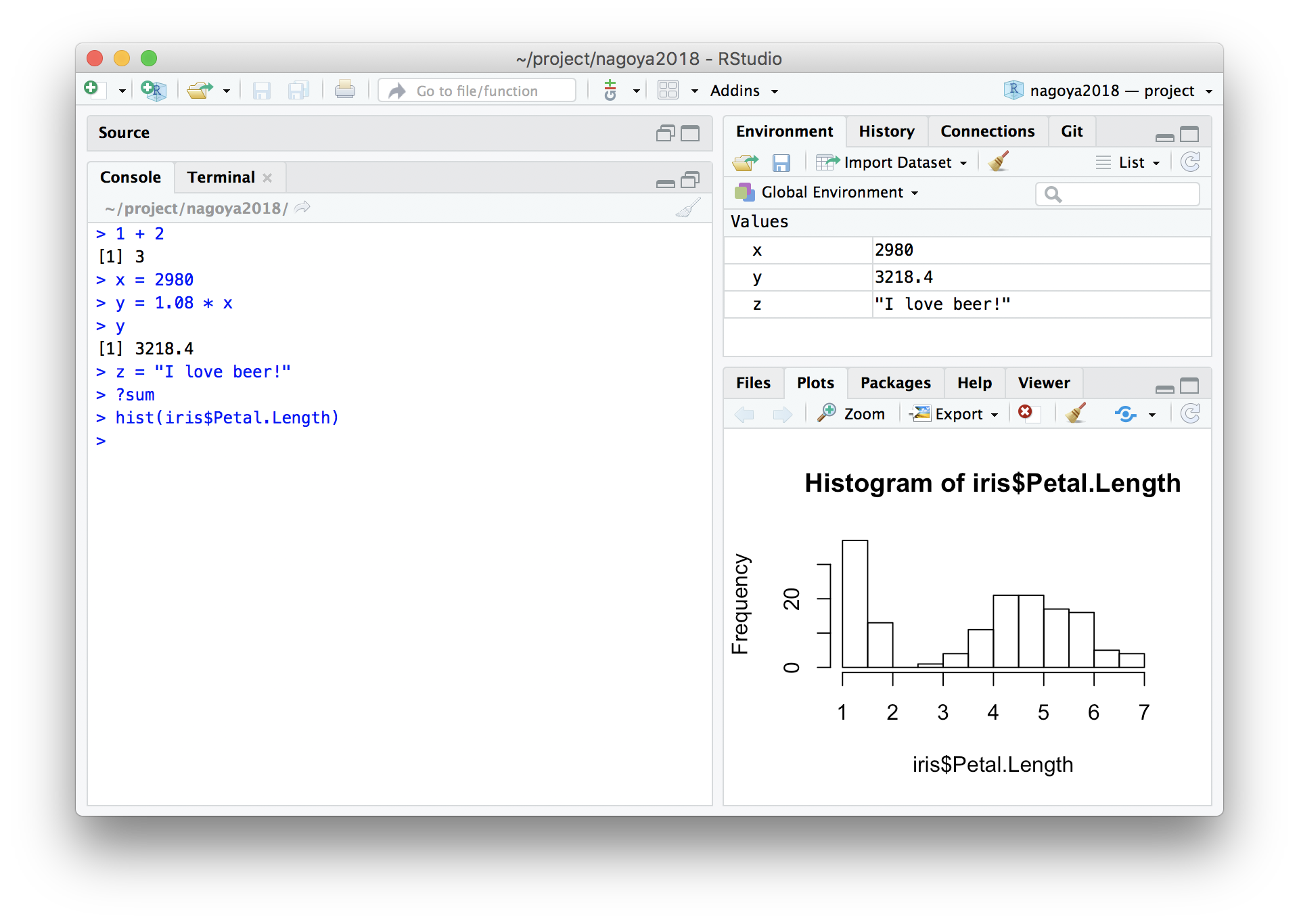
毎回まっさらなワークスペースで始める設定
RStudio → Preferences command,
Tools → Global options
“Restore …” のチェックを外して、 “Save …” のNeverを選択
“Project” を新規作成する
File → New Project… → New Directory → New Project →
→ Directory name: r-training-2021
→ as subdirectory of: ~/project (無ければ作る)
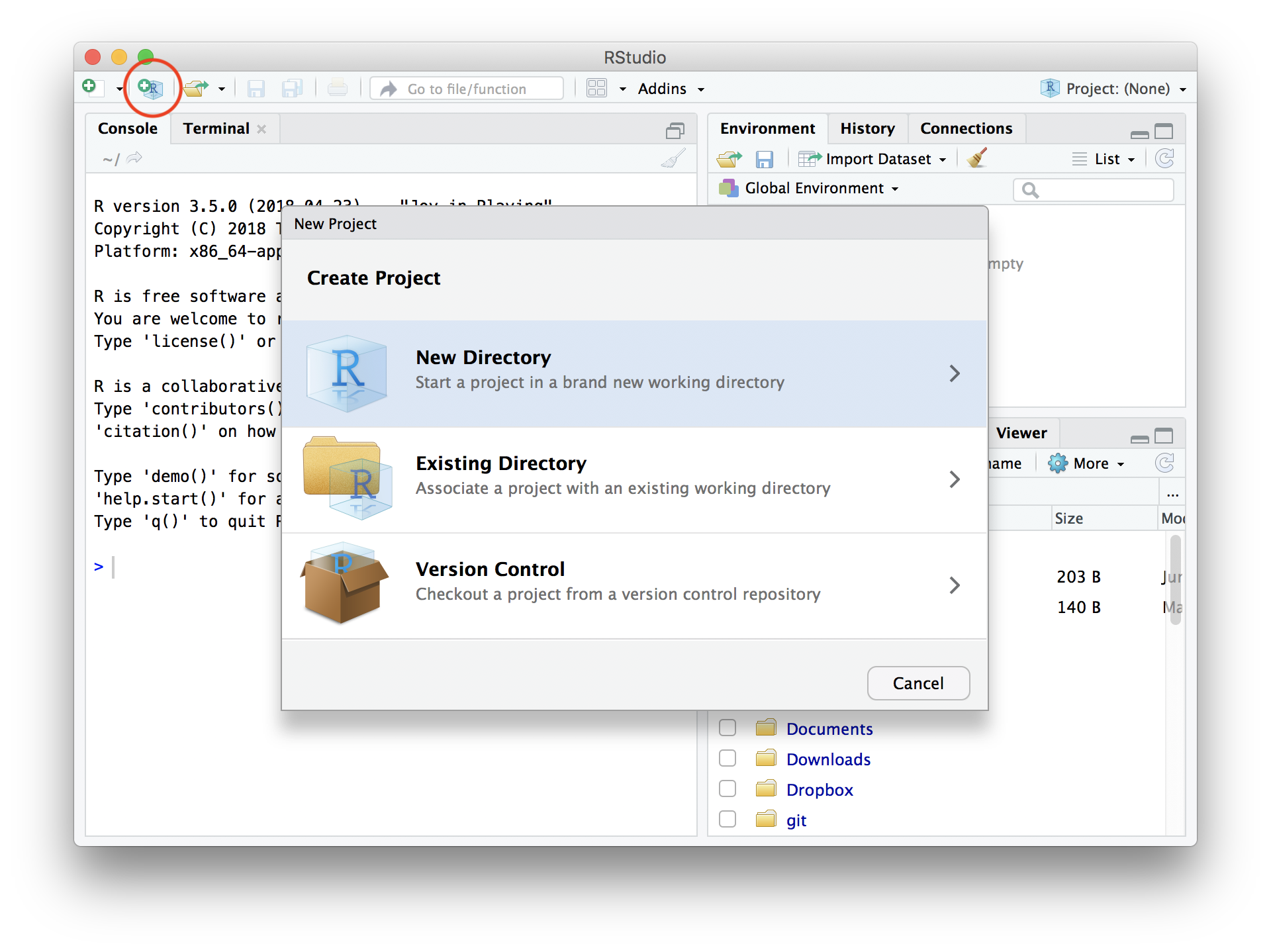
📁 ディレクトリ = フォルダ
Rスクリプトに書いてから実行
File → New File → R script
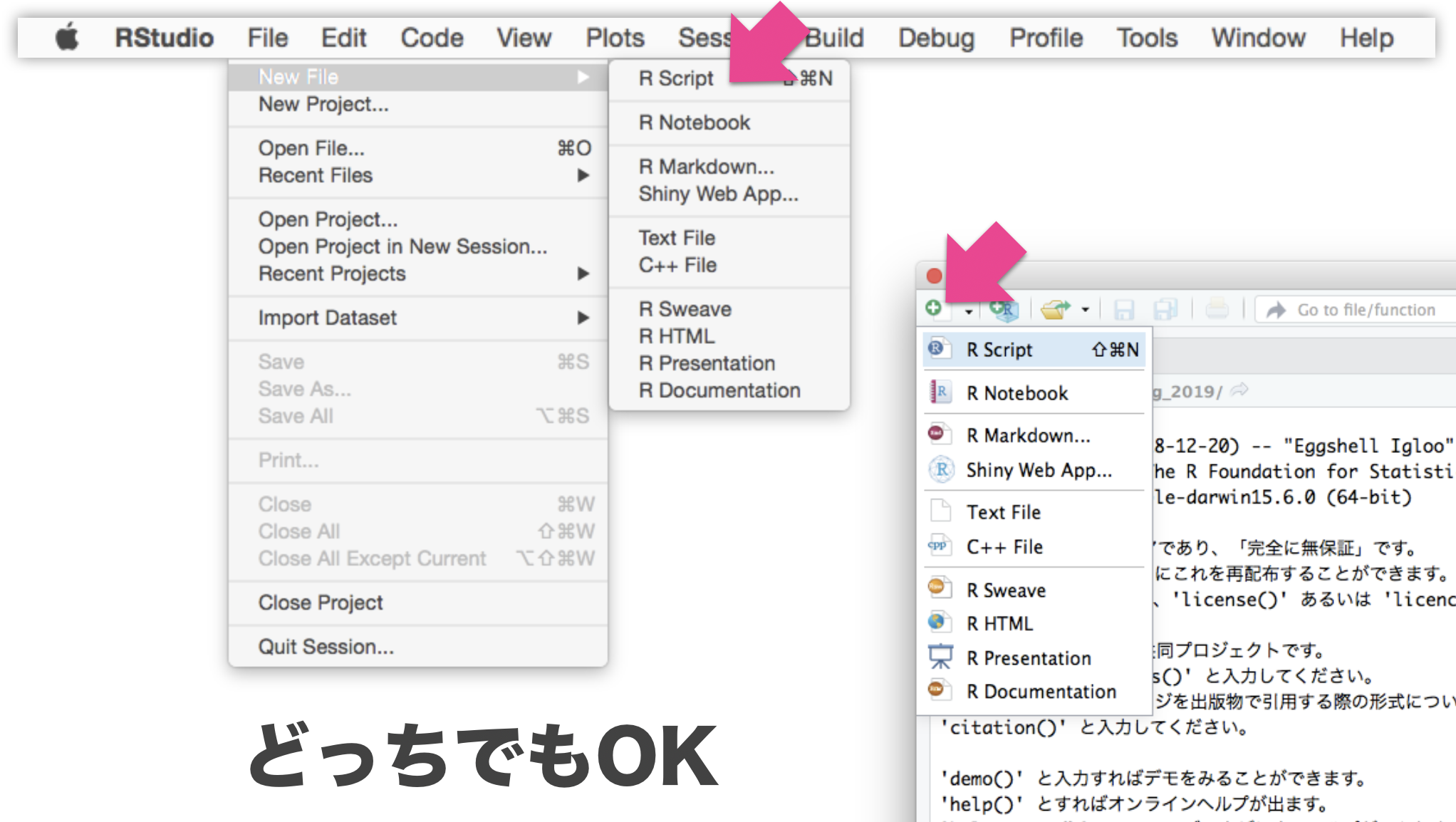
Rスクリプトに書いてから実行
File → New File → R script
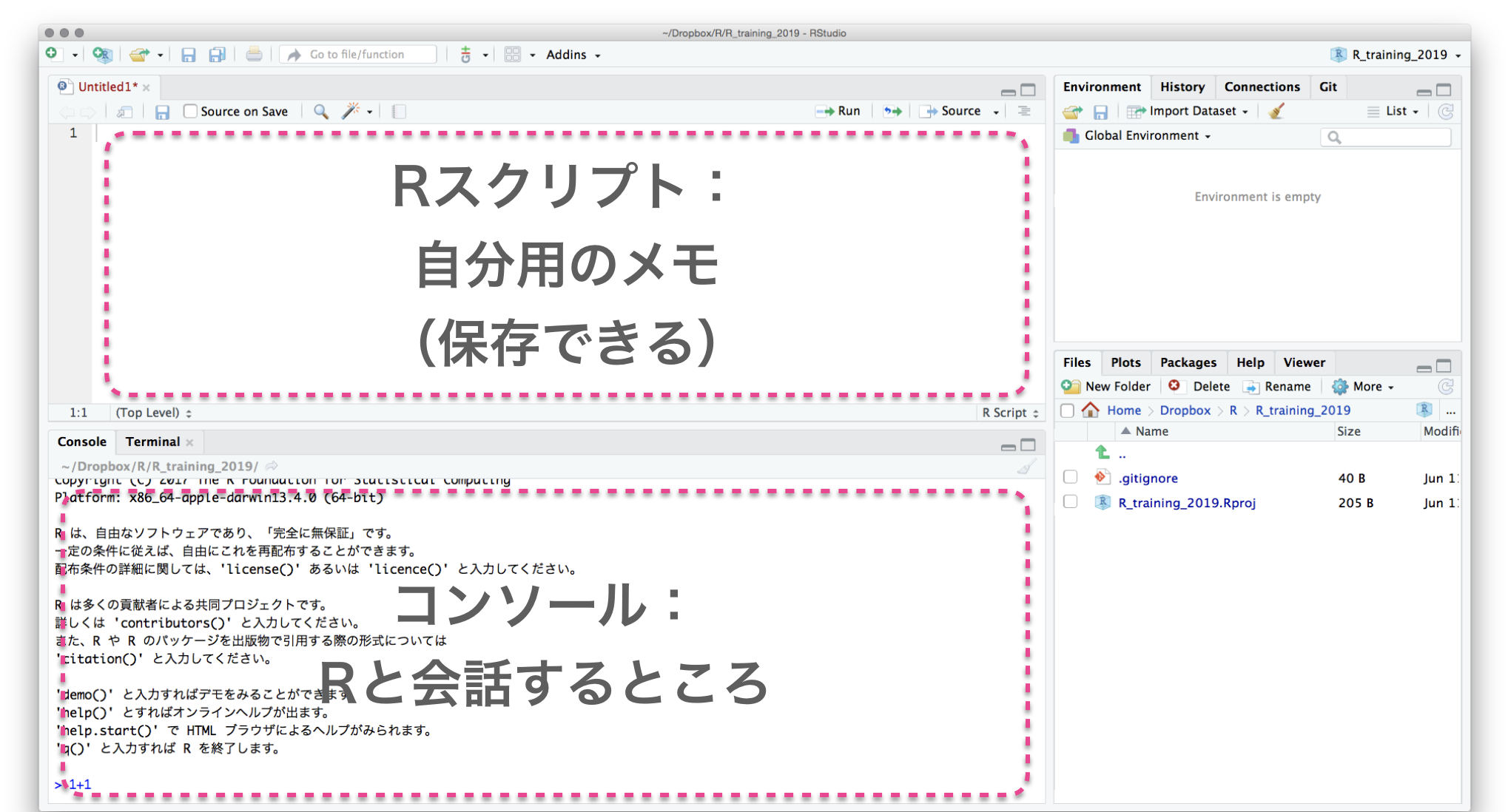
Rスクリプトに書いてから実行
Select text with shift←↓↑→
Execute them with ctrlreturn
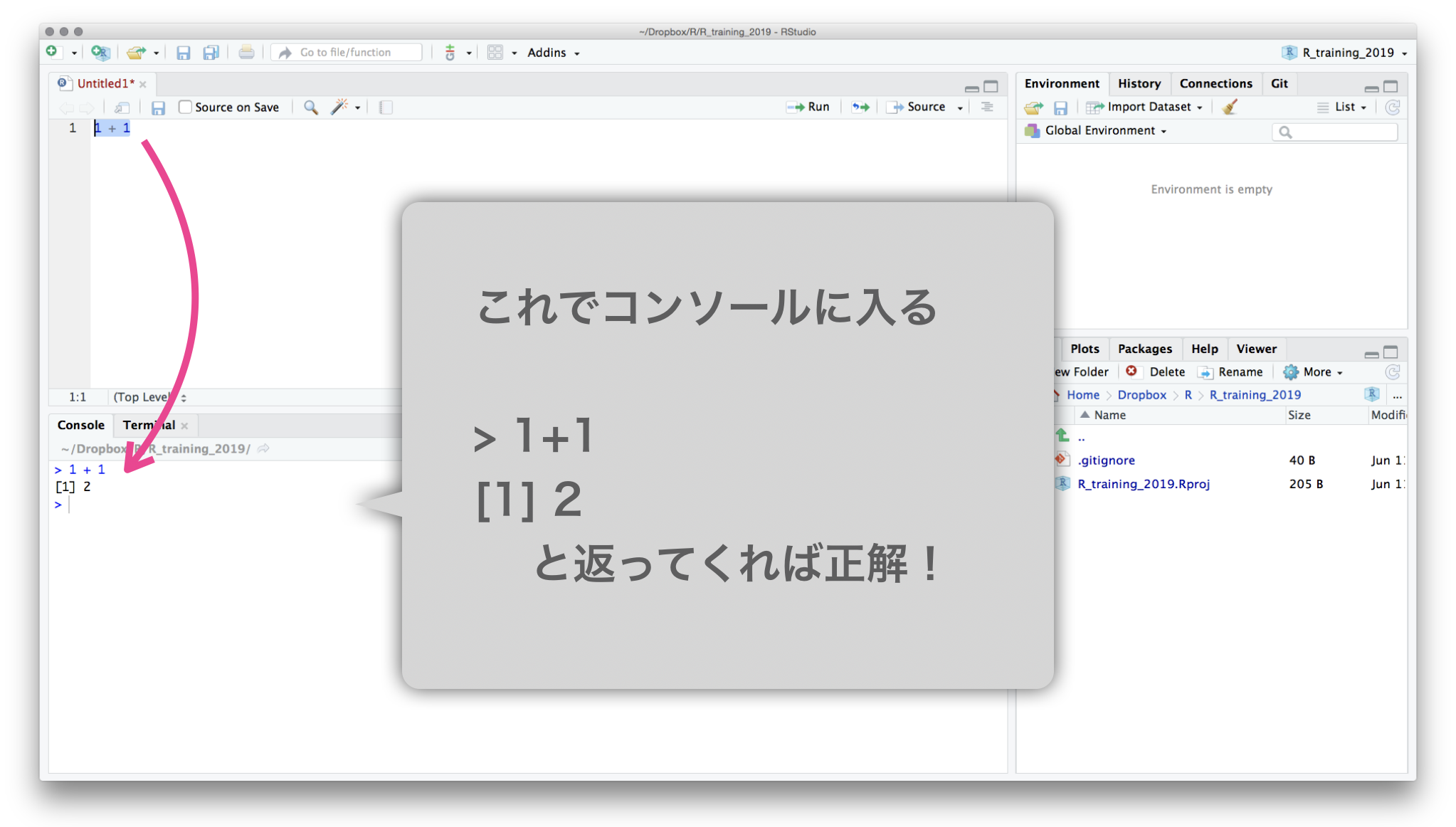
Rスクリプトを保存する
- 手順
- File → Save commands
- ファイル名:
hello.R - 場所: さっき作ったプロジェクト内 (デフォルトでそうなるはず)
- スクリプトを書いたら消さずに保存すること!
- 書いたスクリプトは財産
- 保存しておけばまた使い回せる
🔰 いろんな四則演算を試して hello.R に保存してみよう。
e.g., 1 + 2 + 3, 3 * 7 * 2, 4 / 2, 4 / 3, etc.
プロジェクト📁にファイルが溜まっていく
スクリプト、データ、結果を分けて整理する例:
r-training-2021/ # プロジェクトの最上階
├── r-training-2021.Rproj # これダブルクリックでRStudioを起動
├── hello.R
├── transform.R # データ整理・変形のスクリプト
├── visualize.R # 作図のスクリプト
├── data/ # 元データを置くところ
│ ├── iris.tsv
│ └── diamonds.xlsx
└── output/ # 結果の出力先
├── iris-petal.png
└── iris-summary.tsv
プロジェクト最上階を作業ディレクトリとし、
ファイル読み書きの基準にする。(後で詳しく)
ほんの一例です。好きな構造に決めてください。
Rと接する上での心構え

- エラー文を恐れない
- 熟練プログラマでも頻繁にエラーを起こす。
- エラーはRからのメッセージ。意図を読み取って修正しよう。
- プログラミングの経験値 ≈ エラー解決の経験値
- 困ったらウェブ検索
- あなたの問題は全世界のRユーザーが既に通った道。
- 日本語で、英語で、エラー文そのもので検索すれば解決策に当たる。
この実習の取り組み方
とにかく手を動かして体感しよう!
-
こういう枠が出てきたら、自分のRスクリプトにコピペして保存:
head(iris) -
実行してコンソールを確認。思ったとおりの出力?
ErrorやWarningがあったらよく読んで対処する。
(無視していいWarningもたまーにあるけど) -
🔰 マークの練習問題があれば解いてみる。
そこまでのコードのコピペ+改変でできるはず。
疑問・困りごとがある場合は気軽にChat欄に書き込んでください。
私の代わりに解答するのも大歓迎です助かります。
変数/オブジェクトを作ってみよう
x = 2 # Create x
x # What's in x?
[1] 2
y = 5 # Create y
y # What's in y?
[1] 5
Rでは代入演算子として矢印 <- も使えるけど私は = 推奨。
# 記号より右はRに無視される。コメントを書くのに便利。
x + y
[1] 7
🔰 x と y の引き算、掛け算、割り算をやってみよう
基本的な演算
+ とか * のような演算子(operator)を変数の間に置く。
10 + 3 # addition
10 - 3 # subtraction
10 * 3 # multiplication
10 / 3 # division
10 %/% 3 # integer division
10 %% 3 # modulus 剰余
10 ** 3 # exponent 10^3
🔰 コピペして結果を確認してみよう。
関数 (function)
変数を受け取って、何か仕事して、返す命令セット
x = seq(1, 3) # 1と3を渡すとvectorが返ってくる
x
[1] 1 2 3
sum(x) # vectorを渡すと足し算が返ってくる
[1] 6
square = function(something) { # 自分の関数を定義
something ** 2
}
square(x) # 使ってみる
[1] 1 4 9
🔰 自分の関数を何か作ってみよう。
e.g., 2倍にする関数 twice
変数/オブジェクトを作ってみよう Part 2
x = 42 # Create x
x # What's in x?
[1] 42
y = "24601" # Create y
y # What's in y?
[1] "24601"
この x と y を足そうとするとエラーになる。なぜ?
x + y # Error! Why?
Error in x + y: non-numeric argument to binary operator
変数/オブジェクトの型
class(x)
[1] "numeric"
is.numeric(x)
[1] TRUE
is.character(x)
[1] FALSE
as.character(x)
[1] "42"
🔰 さっき作った y にも同じ関数を適用してみよう。
変数/オブジェクトの型
vector: 基本型。一次元の配列。logical: 論理値 (TRUEorFALSE)numeric: 数値 (整数42Lor 実数3.1416)character: 文字列 ("a string")factor: 因子 (文字列っぽいけど微妙に違う)
array: 多次元配列。vector同様、全要素が同じ型。matrix: 行列 = 二次元の配列。
list: 異なる型でも詰め込める太っ腹ベクトル。data.frame: 同じ長さのベクトルを並べた長方形のテーブル。重要。
tibbleとかtbl_dfと呼ばれる亜種もあるけどほぼ同じ。
vector: 一次元の配列
1個の値でもベクトル扱い。
同じ長さ(または長さ1)の相手との計算が得意。
x = c(1, 2, 9) # 長さ3の数値ベクトル
x + x # 同じ長さ同士の計算
[1] 2 4 18
y = 10 # 長さ1の数値ベクトル
x + y # 長さ3 + 長さ1 = 長さ3 (それぞれ足し算)
[1] 11 12 19
x < 5 # 5より小さいか
[1] TRUE TRUE FALSE
🔰 この x, y を使っていろいろな演算を試してみよう
vectorから部分的に抜き出す
[] を使う。番号は1から始まる。
letters
[1] "a" "b" "c" "d" "e" "f" "g" "h" "i" "j" "k" "l" "m" "n" "o" "p" "q" "r" "s" "t" "u" "v" "w" "x" "y" "z"
letters[3]
[1] "c"
letters[seq(4, 6)] # 4 5 6
[1] "d" "e" "f"
letters[seq(1, 26) < 4] # TRUE TRUE TRUE FALSE FALSE ...
[1] "a" "b" "c"
vectorを渡した結果は関数によって異なる
各要素に適用するもの:
x = c(1, 2, 9)
y = sqrt(x) # square root
y
[1] 1.000000 1.414214 3.000000
全要素を集約した値を返すもの:
z = sum(x)
z
[1] 12
🔰 log(), exp(), length(), max(), mean()
にvectorを渡してみよう。
matrix: 二次元の配列 (行列)
1本のvectorを折り曲げて長方形にしたもの。
中身は全て同じ型。機械学習とか画像処理とかで使う。
v = seq(1, 8) # c(1, 2, 3, 4, 5, 6, 7, 8)
x = matrix(v, nrow = 2) # 2行に畳む。列ごとに詰める
x
[,1] [,2] [,3] [,4]
[1,] 1 3 5 7
[2,] 2 4 6 8
y = matrix(v, nrow = 2, byrow = TRUE) # 行ごとに詰める
y
[,1] [,2] [,3] [,4]
[1,] 1 2 3 4
[2,] 5 6 7 8
🔰 結果を確認してみよう: x + y, dim(x), nrow(x), ncol(x).
行 (row), 列 (column) の憶え方


data.frame: 長方形のテーブル (重要!)
同じ長さの列vectorを複数束ねた長方形の表。
e.g., 長さ150の数値ベクトル4本と因子ベクトル1本:
print(iris)
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
<dbl> <dbl> <dbl> <dbl> <fct>
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
--
147 6.3 2.5 5.0 1.9 virginica
148 6.5 3.0 5.2 2.0 virginica
149 6.2 3.4 5.4 2.3 virginica
150 5.9 3.0 5.1 1.8 virginica
iris はアヤメ属3種150個体に関する測定データ。
Rに最初から入ってて、例としてよく使われる。
data.frameを眺める
概要を掴む:
head(iris, 6) # 先頭だけ見てみる。末尾は tail()
nrow(iris) # 行数: Number of ROWs
ncol(iris) # 列数: Number of COLumns
names(iris) # 列名
summary(iris) # 要約
View(iris) # RStudioで閲覧
str(iris) # 構造が分かる形で表示
'data.frame': 150 obs. of 5 variables:
$ Sepal.Length: num 5.1 4.9 4.7 4.6 5 5.4 4.6 5 4.4 4.9 ...
$ Sepal.Width : num 3.5 3 3.2 3.1 3.6 3.9 3.4 3.4 2.9 3.1 ...
$ Petal.Length: num 1.4 1.4 1.3 1.5 1.4 1.7 1.4 1.5 1.4 1.5 ...
$ Petal.Width : num 0.2 0.2 0.2 0.2 0.2 0.4 0.3 0.2 0.2 0.1 ...
$ Species : Factor w/ 3 levels "setosa","versicolor",..: 1 1 1 1 1 1 1 1 1 1 ...
🔰 ほかのデータもいろいろ見てみよう。
e.g., mtcars, quakes, data()
data.frameを眺める
部分的なdata.frameを取得する:
iris[2, ] # 2行目
iris[2:5, ] # 2行目から5行目まで
iris[, 3:4] # 3-4列目
iris[2:5, 3:4] # 2-5行目, 3-4列目
vectorとして取得する:
iris[[3]] # 3列目
iris$Petal.Length # Petal.Length列
iris[["Petal.Length"]] # Petal.Length列
iris[["Petal.Length"]][2] # Petal.Length列の2番目
結果がdata.frameになるかvectorになるか微妙:
iris[, 3] # 3列目
iris[, "Petal.Length"] # Petal.Length列
iris[2, 3] # 2行目3列目
iris[2, "Petal.Length"] # 2行目Petal.Length列
data.frameの新規作成
同じ長さの 列(column) vector を結合して作る:
x = c(1, 2, 3)
y = c("A", "B", "C")
mydata = data.frame(x, y)
print(mydata)
x y
1 1 A
2 2 B
3 3 C
🔰 次のようなdata.frameを作って theDF と名付けよう:
i s
24 x
25 y
26 z
ヒント: c() 無しでクリアすることも可能。
data.frameの読み書き
-
readxlパッケージを使えば
.xlsxファイルも読める、けど -
カンマ区切り(CSV)とかタブ区切り(TSV)のテキストが無難。
-
ファイル名は作業ディレクトリからの相対パスで指定。
install.packages("readr") # R標準の read.table() とかは難しいので library(readr) # パッケージのやつを使うよ write_tsv(iris, "data/iris.tsv") # 書き出し iris2 = read_tsv("data/iris.tsv") # 読み込み -
現在の作業ディレクトリとその中身を確認しておこう:
getwd() # Get Working Directory list.files(".") # List files in "." list.files("data") # List files in "./data"
🔰 R組み込みデータや自作データを読み書きしてみよう
R package
便利な関数やデータセットなどをひとまとめにしたもの。
- Standard Packages
- Rの標準機能。何もしなくても使用可能
- Contributed Packages
- 有志により開発され、 CRAN にまとめて公開されている。
- 要インストール。使う前に読み込むおまじないが必要。
install.packages("readr") # 一度やればOK
library(readr) # 読み込みはRを起動するたびに必要
update.packages() # たまには更新しよう
- 素のRも覚えきってないのにいきなりパッケージ?
- 大丈夫。誰も覚えきってない。
- パッケージを使わないR作業 = 火もナイフも使わない料理
tidyverse
Rでデータを上手に扱うためのパッケージ群
install.packages("tidyverse")
library(tidyverse)
# 関連パッケージが一挙に読み込まれる
- 統一的な使い勝手
- 暗黙の処理をなるべくしない安全設計
- シンプルな関数を繋げて使うデザイン
tidyverse
Rでデータを上手に扱うためのパッケージ群
install.packages("tidyverse")
library(tidyverse)
# 関連パッケージが一挙に読み込まれる
Conflicts ❌とか表示されて不安だけど
これは大丈夫なやつ:
── Attaching packages ──────────────────────── tidyverse 1.3.1 ──
✔ ggplot2 3.3.5 ✔ purrr 0.3.4
✔ tibble 3.1.5 ✔ dplyr 1.0.7
✔ tidyr 1.1.4 ✔ stringr 1.4.0
✔ readr 2.0.2 ✔ forcats 0.5.1
── Conflicts ─────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
次回からはこれらを使って解説
疑問やエラーの解決方法
- エラーのほとんどは凡ミス由来。よく確認しよう。
- エラー文をちゃんと読む:
No such file or directory - よくあるエラー集 (石川由希さん@名古屋大) をチェックする
- 変数の中身を確かめる:
str(iris),attributes(iris)
- エラー文をちゃんと読む:
- エラー文やパッケージ名をコピペしてウェブ検索
→ StackOverflow や個人サイトに解決策 - Slack
r-wakalang で質問を投稿する。
(質問に飢えた優しいワニが多数生息 👀 👀 👀 👀) - 状況再現できる小さな例
(reprex)
を添えると回答を得やすい。
(これを準備してるうちに問題が切り分けられて自己解決したり) - パッケージの公式ドキュメントをちゃんと読む
- R(Studio)内のヘルプを読む:
?sum,help.start()
本日1時限目の話題
✅ なぜRを使うのか?
✅ データ解析全体の流れ。可視化だいじ (詳細は本日後半)
✅ 作図・解析の前にデータの前処理が必要 (詳細は明日)
✅ Rの基礎
- まずRスクリプトに書いてから、コンソールで実行
- 変数には型がある: 数値、文字列、データフレームなど
- 便利なパッケージを使おう
- 調べ方さえわかれば、全部覚えなくても大丈夫。
Reference
- R for Data Science — Hadley Wickham and Garrett Grolemund
- https://r4ds.had.co.nz/
- Book
- 日本語版書籍(Rではじめるデータサイエンス)
- Older versions
- 「Rにやらせて楽しよう — データの可視化と下ごしらえ」 岩嵜航 2018
- 「Rを用いたデータ解析の基礎と応用」石川由希 2019 名古屋大学
- 「Rによるデータ前処理実習」 岩嵜航 2020 東京医科歯科大
- 「Rを用いたデータ解析の基礎と応用」 石川由希 2021 名古屋大学